文档首页 → 开发应用程序 → Python 驱动程序 → PyMongo
存储大文件
概述
在本指南中,您可以学习如何使用 GridFS 在MongoDB中存储和检索大文件。GridFS 是由PyMongo实现的规范,它描述了在存储文件时如何将其分割成块,并在检索时重新组装它们。驱动程序对GridFS的实现是一个抽象,它管理文件存储的操作和组织。
如果您的文件大小超过16MB的BSON文档大小限制,应使用GridFS。有关GridFS是否适合您的用例的更多信息,请参阅MongoDB服务器手册中的GridFS。
以下部分描述了GridFS操作及其执行方法。
GridFS工作原理
GridFS将文件组织在存储桶中,存储桶是一组包含文件块及其描述信息的MongoDB集合。存储桶包含以下集合,使用GridFS规范中定义的约定命名:
以下是
chunks集合存储二进制文件块。files集合存储文件元数据。
当你创建一个新的GridFS存储桶时,驱动程序会创建上述集合,以默认存储桶名称fs为前缀,除非你指定了不同的名称。驱动程序还会为每个集合创建索引,以确保文件及其相关元数据的有效检索。驱动程序仅在执行第一次写入操作时创建GridFS存储桶,如果它不存在。只有当索引不存在且存储桶为空时,驱动程序才创建索引。有关GridFS索引的更多信息,请参阅MongoDB服务器手册中的GridFS索引。
使用GridFS存储文件时,驱动程序会将文件拆分为更小的块,每个块由chunks集合中的单独文档表示。它还在files集合中创建一个文档,其中包含文件ID、文件名和其他文件元数据。您可以从内存或从流中上传文件。请参阅以下图表以了解GridFS在将文件上传到存储桶时如何拆分文件。

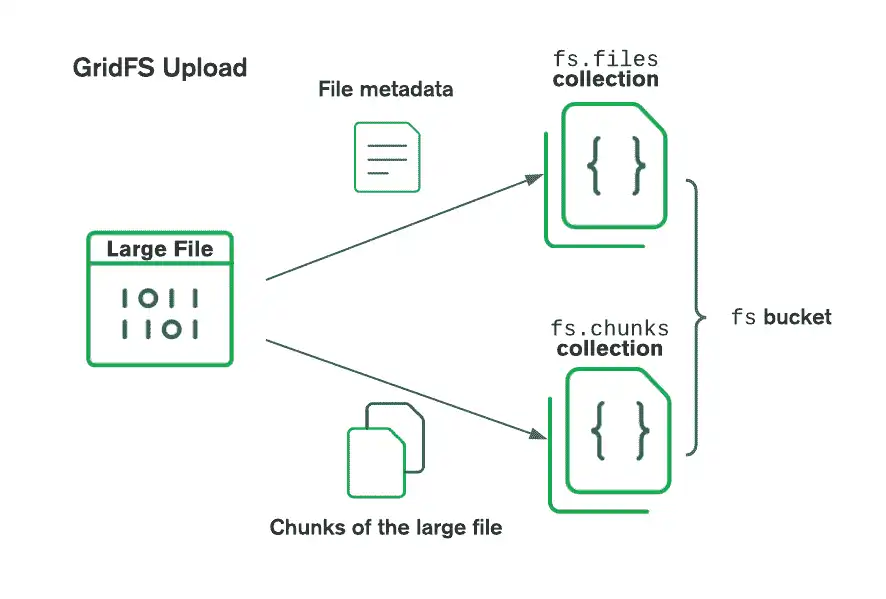
检索文件时,GridFS从指定存储桶中的files集合获取元数据,并使用这些信息从chunks集合中的文档重建文件。您可以读取文件到内存或将输出到流中。
创建GridFS存储桶
要存储或从GridFS检索文件,请通过调用GridFSBucket()构造函数并传入一个Database实例来创建一个GridFS存储桶。您可以使用GridFSBucket实例对存储桶中的文件执行读写操作。
const db = client.db(dbName); const bucket = new mongodb.GridFSBucket(db);
要创建或引用具有除默认名称fs之外的自定义名称的存储桶,请将存储桶名称作为第二个参数传递给GridFSBucket()构造函数,如下所示
const bucket = new mongodb.GridFSBucket(db, { bucketName: 'myCustomBucket' });
上传文件
使用GridFSBucket类中的open_upload_stream()方法为给定文件名创建一个上传流。该方法允许您指定配置信息,例如文件块大小和其他字段/值对,作为元数据存储。将选项作为open_upload_stream()的参数设置,如下所示
fs.createReadStream('./myFile'). pipe(bucket.openUploadStream('myFile', { chunkSizeBytes: 1048576, metadata: { field: 'myField', value: 'myValue' } }));
检索文件信息
在本节中,您可以了解如何检索存储在GridFS存储桶的files集合中的文件元数据。元数据包含有关所引用文件的信息,包括:
文件的
_id文件名
文件长度/大小
上传日期和时间
一个
metadata文档,您可以在其中存储任何其他信息
要从GridFS存储桶中检索文件,请在GridFSBucket实例上调用find()方法。此方法返回一个Cursor实例,您可以通过它访问结果。有关PyMongo中Cursor对象的更多信息,请参阅从游标访问数据。
以下代码示例展示了如何检索并打印GridFS存储桶中所有文件的元数据。它使用for...of语法遍历Cursor可迭代对象并显示结果
const cursor = bucket.find({}); for await (const doc of cursor) { console.log(doc); }
find()方法接受各种查询规范。您可以使用其参数来指定排序顺序、要返回的最大文档数以及返回之前要跳过的文档数。有关查询MongoDB的更多信息,请参阅检索数据。
下载文件
您可以通过使用来自GridFSBucket的open_download_stream_by_name()方法来创建一个下载流,从而从您的MongoDB数据库中下载文件。
以下示例展示了如何将存储在filename字段中的文件名引用的文件下载到您的当前工作目录
bucket.openDownloadStreamByName('myFile'). pipe(fs.createWriteStream('./outputFile'));
注意
如果有多个文档具有相同的filename值,GridFS将流式传输具有给定名称的最新文件(根据uploadDate字段确定)。
或者,您可以使用接受文件_id字段作为参数的open_download_stream()方法
bucket.openDownloadStream(ObjectId("60edece5e06275bf0463aaf3")). pipe(fs.createWriteStream('./outputFile'));
注意
GridFS流式API不能加载部分块。当下载流需要从MongoDB中拉取一个块时,它会将整个块拉入内存。默认的255千字节块大小通常足够,但您可以减小块大小以减少内存开销。
重命名文件
使用rename()方法更新您存储桶中GridFS文件的名称。您必须通过文件的_id字段而不是其文件名来指定要重命名的文件。
以下示例展示了如何通过引用文档的_id字段来更新filename字段为"newFileName"
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");
注意
rename()方法支持一次性更新一个文件的名称。要重命名多个文件,从存储桶中检索匹配文件名的文件列表,从您想要重命名的文件中提取_id字段,并将每个值分别传递给rename()方法的单独调用。
删除文件
使用delete()方法从您的存储桶中删除文件的集合文档和相关块。这实际上会删除文件。您必须通过文件的_id字段而不是其文件名来指定文件。
以下示例展示了如何通过引用其_id字段来删除文件
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");
注意
《delete()` 方法仅支持一次性删除一个文件。要删除多个文件,请从存储桶中检索文件,从您要删除的文件中提取 _id 字段,并将每个值分别调用 delete() 方法。
API 文档
要了解更多关于使用 PyMongo 存储和检索大型文件的信息,请参阅以下 API 文档