解释 Explain 计划结果
本页
您可以使用解释结果确定以下有关查询的信息
查询完成所需的时间
查询是否使用了索引
为满足查询而扫描的文档和索引键的数量
注意
查询的解释计划结果在不同版本的 MongoDB 之间可能会有所变化。
关于cursor.explain("executionStats") 和 db.collection.explain("executionStats") 方法提供了关于查询性能的统计信息。这些统计信息可以用来衡量查询是否以及如何使用索引。有关详细信息,请参阅 db.collection.explain()。
MongoDB Compass提供了一个Explain Plan 选项卡,该选项卡显示了查询性能的统计信息。这些统计信息可以用来衡量查询是否以及如何使用索引。
评估查询性能
考虑一个包含以下文档的集合 inventory
{ "_id" : 1, "item" : "f1", type: "food", quantity: 500 } { "_id" : 2, "item" : "f2", type: "food", quantity: 100 } { "_id" : 3, "item" : "p1", type: "paper", quantity: 200 } { "_id" : 4, "item" : "p2", type: "paper", quantity: 150 } { "_id" : 5, "item" : "f3", type: "food", quantity: 300 } { "_id" : 6, "item" : "t1", type: "toys", quantity: 500 } { "_id" : 7, "item" : "a1", type: "apparel", quantity: 250 } { "_id" : 8, "item" : "a2", type: "apparel", quantity: 400 } { "_id" : 9, "item" : "t2", type: "toys", quantity: 50 } { "_id" : 10, "item" : "f4", type: "food", quantity: 75 }
文档以以下顺序出现MongoDB Compass如下所示

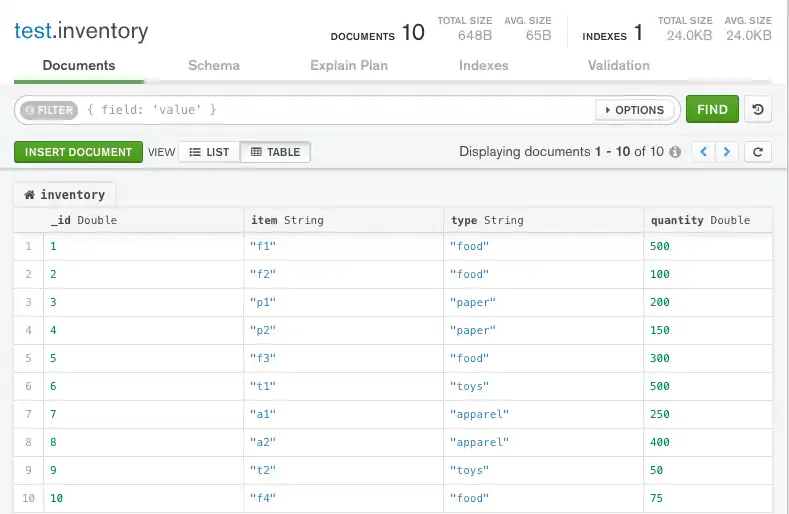
无索引查询
以下查询检索了 quantity 字段值在 100 和 200 之间(包括100和200)的文档
db.inventory.find( { quantity: { $gte: 100, $lte: 200 } } )
查询返回以下文档
{ "_id" : 2, "item" : "f2", "type" : "food", "quantity" : 100 } { "_id" : 3, "item" : "p1", "type" : "paper", "quantity" : 200 } { "_id" : 4, "item" : "p2", "type" : "paper", "quantity" : 150 }
要查看选择的查询计划,请将 cursor.explain("executionStats") 游标方法链接到 find 命令的末尾
db.inventory.find( { quantity: { $gte: 100, $lte: 200 } } ).explain("executionStats")
explain() 返回以下结果
{ queryPlanner: { ... winningPlan: { queryPlan: { stage: 'COLLSCAN', ... } } }, executionStats: { executionSuccess: true, nReturned: 3, executionTimeMillis: 0, totalKeysExamined: 0, totalDocsExamined: 10, executionStages: { stage: 'COLLSCAN', ... }, ... }, ... }
queryPlanner.winningPlan.queryPlan.stage显示COLLSCAN以表示集合扫描。集合扫描表示
mongod必须逐个文档地扫描整个集合以识别结果。这是一个通常很昂贵的操作,可能会导致查询变慢。executionStats.nReturned显示3以表示获胜的查询计划返回三个文档。executionStats.totalKeysExamined显示0以表示此查询未使用索引。executionStats.totalDocsExamined显示10以表示 MongoDB 必须扫描十个文档(即集合中的所有文档)以找到三个匹配的文档。
以下查询检索了 quantity 字段值在 100 和 200 之间(包括100和200)的文档
将以下过滤器复制到 Compass 查询栏中,然后点击查找:
{ quantity: { $gte: 100, $lte: 200 } }
查询返回以下文档
以查看选定的查询计划
单击
test.inventory集合的 Explain Plan 选项卡。单击 Explain。
MongoDB Compass如下显示查询计划

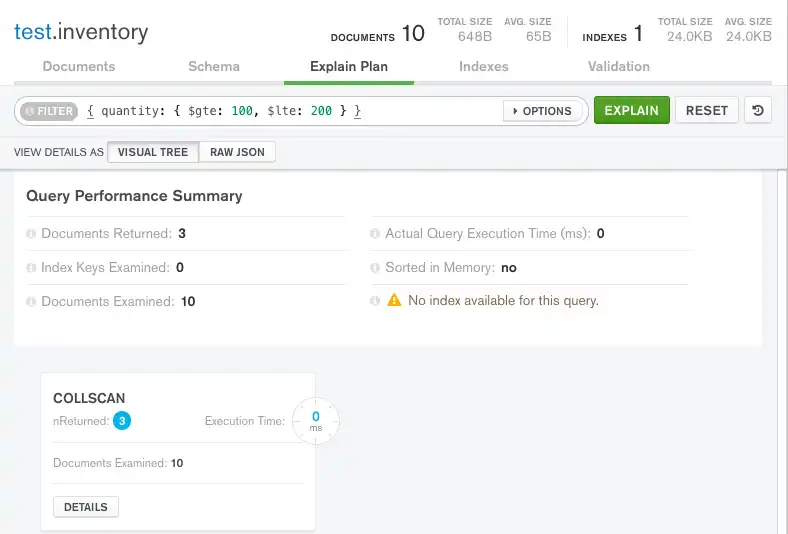
注意
由于我们在此教程中使用的数据集非常小,因此 实际查询执行时间 显示 0 秒,尽管我们没有使用索引。
在更大的数据集中,索引查询与非索引查询之间的查询执行时间差异将更加显著。
视觉树
查询性能摘要 显示查询的执行统计信息
返回文档数 显示
3以表示获胜的查询计划返回三个文档。索引键检查 显示
0以表示此查询未使用索引。检查的文档数 显示
10以表示 MongoDB 必须扫描十个文档(即集合中的所有文档)以找到三个匹配的文档。
在 查询性能摘要 下方MongoDB Compass显示
COLLSCAN查询阶段以表示为此查询使用了集合扫描。集合扫描表示
mongod必须逐个文档地扫描整个集合以识别结果。这是一个通常很昂贵的操作,可能会导致查询变慢。
原始JSON
详细信息也可以通过点击查询栏下方的 原始JSON 以原始JSON格式查看

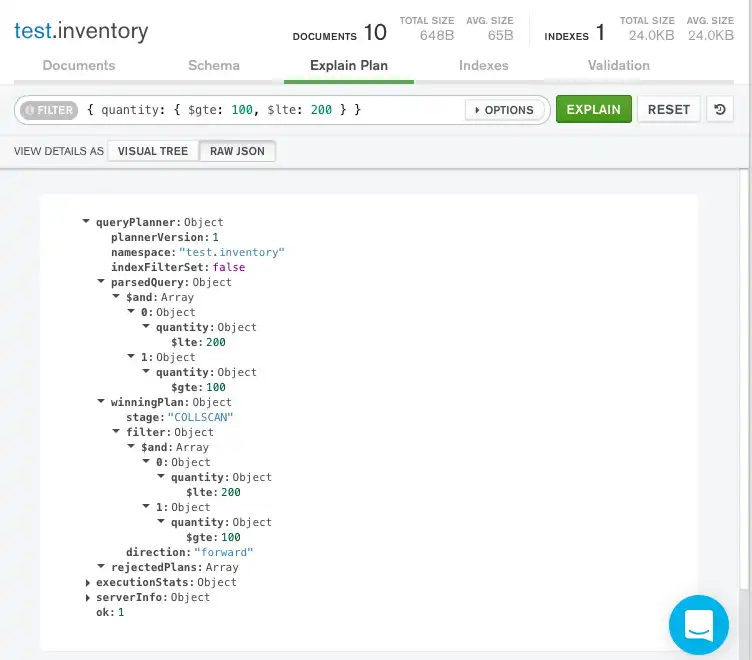
匹配文档数与检查文档数之间的差异可能表明,为了提高效率,查询可能需要使用索引。
带有索引的查询
为了支持在 数量 字段上的查询,请在 数量 字段上添加索引
db.inventory.createIndex( { quantity: 1 } )
要查看查询计划统计信息,请使用 explain() 方法
db.inventory.find( { quantity: { $gte: 100, $lte: 200 } } ).explain("executionStats")
explain() 方法返回以下结果
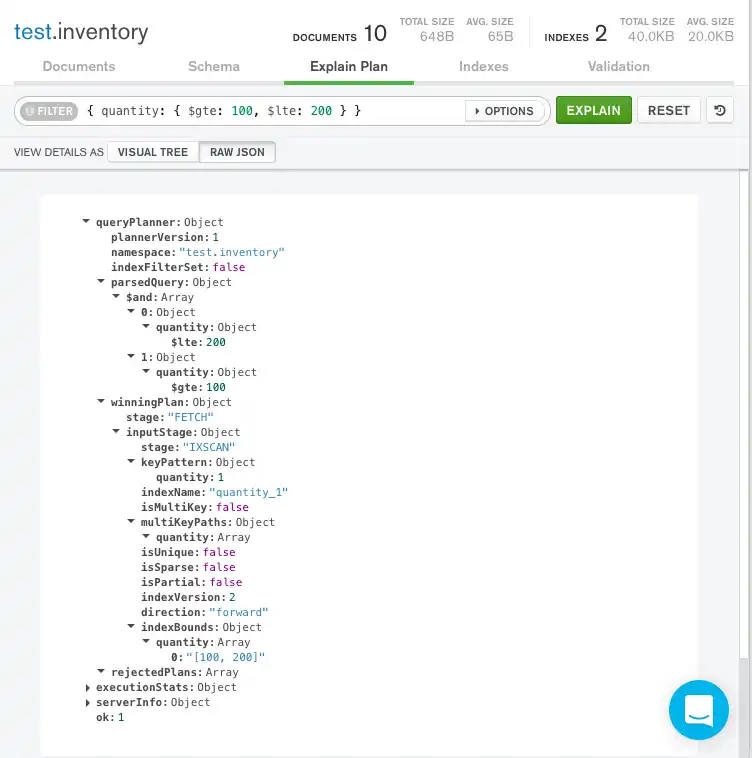
{ queryPlanner: { ... winningPlan: { queryPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { quantity: 1 }, ... } } }, rejectedPlans: [ ] }, executionStats: { executionSuccess: true, nReturned: 3, executionTimeMillis: 0, totalKeysExamined: 3, totalDocsExamined: 3, executionStages: { ... }, ... }, ... }
queryPlanner.winningPlan.queryPlan.inputStage.stage显示IXSCAN以指示使用索引。executionStats.nReturned显示3以表示获胜的查询计划返回三个文档。executionStats.totalKeysExamined显示3以指示 MongoDB 扫描了三个索引条目。检查的键数与返回的文档数相匹配,这意味着mongod只需检查索引键即可返回结果。mongod不需要扫描所有文档,只需将三个匹配的文档拉入内存。这导致查询非常高效。executionStats.totalDocsExamined显示3以指示 MongoDB 扫描了三个文档。
单击
test.inventory集合的 索引 选项卡。单击 创建索引。
从 选择字段名 下拉列表中选择
数量。从类型下拉列表中选择
1 (asc)。单击 创建。
注意
如果留空索引名称字段,则MongoDB Compass将创建一个默认索引名称。
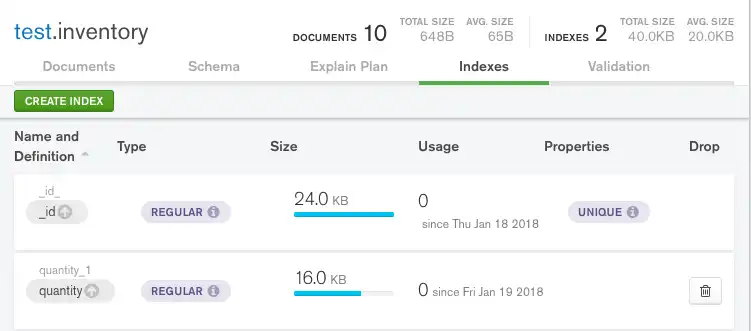
现在您可以在索引选项卡中看到您刚刚创建的索引

返回到执行计划选项卡,重新运行上一个步骤中的查询,针对inventory集合
{ quantity: { $gte: 100, $lte: 200 } }
MongoDB Compass如下显示查询计划

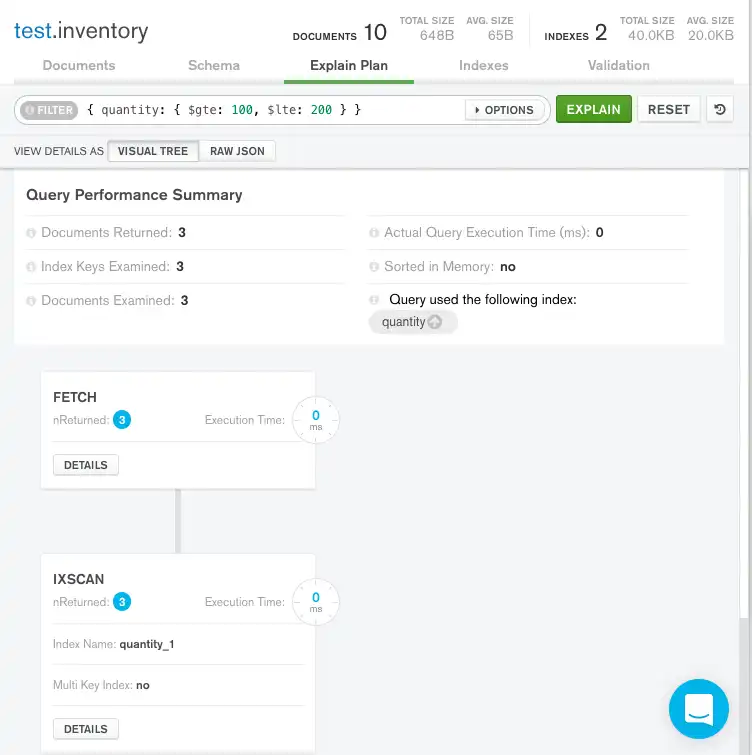
可视化树
查询性能摘要 显示查询的执行统计信息
返回文档数 显示
3以表示获胜的查询计划返回三个文档。检查的索引键显示
3,表示MongoDB扫描了三个索引条目。检查的键的数量与返回的文档数量相匹配,这意味着mongod只需检查索引键即可返回结果。mongod无需扫描所有文档,只需将三个匹配的文档拉入内存。这导致查询非常高效。检查的文档显示
3,表示MongoDB扫描了三个文档。在查询性能摘要的右侧MongoDB Compass显示查询使用了
quantity索引。
在 查询性能摘要 下方MongoDB Compass显示查询阶段
FETCH和IXSCAN。IXSCAN表示在执行FETCH阶段并检索文档之前,mongod使用了索引来满足查询。
原始JSON
详细信息也可以通过点击查询栏下方的 原始JSON 以原始JSON格式查看

如果没有索引,查询将扫描包含10个文档的整个集合以返回3个匹配的文档。查询还必须扫描每个文档的全部内容,可能将它们拉入内存。这会导致昂贵的查询操作,并且可能很慢。
当使用索引运行时,查询扫描了3个索引条目和3个文档以返回3个匹配的文档,从而实现了非常高效的查询。