GridFS
概述
在本指南中,您可以了解如何使用 GridFS 规范在 MongoDB 中存储和检索大文件。GridFS 将大文件拆分为块,并将每个块作为单独的文档存储。当您查询 GridFS 以获取文件时,驱动程序会根据需要组装这些块。GridFS 的驱动程序实现是一种抽象,它管理文件存储的操作和组织。
如果您的文件大小超过 16 MB 的 BSON 文档大小限制,请使用 GridFS。GridFS 还可以帮助您在不将整个文件加载到内存的情况下访问文件。有关 GridFS 是否适合您的用例的更多信息,请参阅GridFS 服务器手册页面.
GridFS 的工作原理
GridFS 以 桶 的形式组织文件,桶是一组包含文件块及其描述信息的 MongoDB 集合。桶包含以下集合
的
chunks集合,用于存储二进制文件块。files集合,用于存储文件元数据。
当您创建新的 GridFS 桶时,驱动程序会创建上述集合。默认桶名称 fs 是集合名称的前缀,除非您指定了不同的桶名称。驱动程序在第一次写入操作期间创建新的 GridFS 桶。
驱动程序还在每个集合上创建索引,以确保高效检索文件和相关元数据。如果索引不存在且桶为空,驱动程序将创建索引。有关 GridFS 索引的更多信息,请参阅服务器手册页面上的 GridFS 索引。
使用 GridFS 存储文件时,驱动程序将文件拆分为更小的块,每个块由 chunks 集合中的单独文档表示。它还在 files 集合中创建一个文档,该文档包含文件 ID、文件名和其他文件元数据。以下图示显示了 GridFS 如何拆分上传的文件

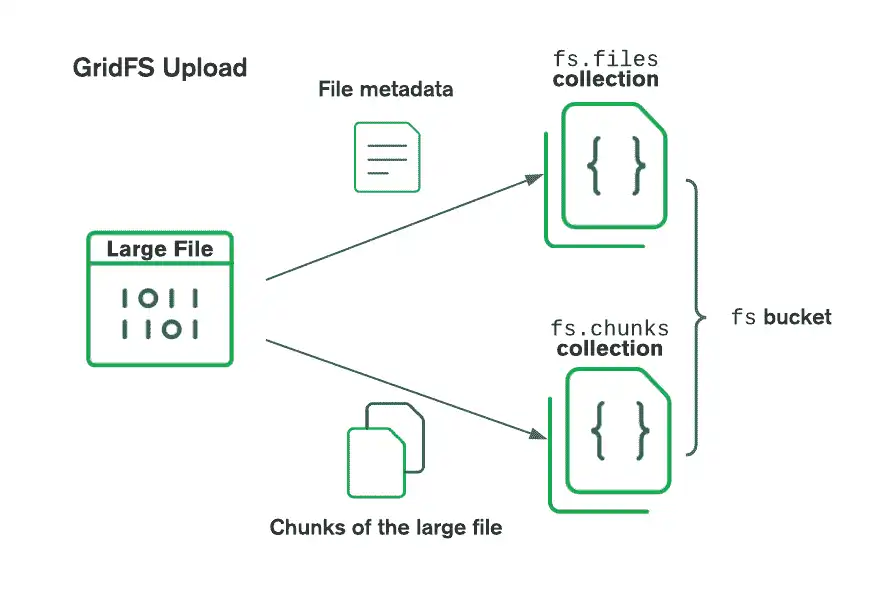
在检索文件时,GridFS从指定桶中的files集合中获取元数据,然后使用该信息从chunks集合中的文档中重建文件。您可以将文件读取到内存中或将它输出到流中。
使用GridFS
要了解GridFS操作及其执行方式,请参阅以下章节
创建GridFS桶
要存储或从GridFS检索文件,请创建一个桶或在MongoDB数据库上获取现有桶的引用。要创建GridFSBucket实例,使用数据库参数调用NewBucket()方法
db := client.Database("db") bucket, err := gridfs.NewBucket(db) if err != nil { panic(err) }
注意
如果GridFS桶已经存在,则NewBucket()方法返回桶的引用,而不是实例化一个新的桶。
默认情况下,新桶的名称为fs。要使用自定义名称实例化桶,请在BucketOptions实例上调用SetName()方法,如下所示
db := client.Database("db") opts := options.GridFSBucket().SetName("custom name") bucket, err := gridfs.NewBucket(db, opts) if err != nil { panic(err) }
上传文件
您可以通过以下方式之一将文件上传到GridFS存储桶:
使用
UploadFromStream()方法,该方法从输入流中读取。使用
OpenUploadStream()方法,该方法写入输出流。
对于这两种上传过程,您可以在UploadOptions实例上指定配置信息。要获取完整的UploadOptions字段列表,请访问API文档。
使用输入流上传
要使用输入流上传文件,请使用以下参数的UploadFromStream()方法
您的文件名
一个
io.Reader,其中包含作为参数打开的文件一个可选的
opts参数,用于修改UploadFromStream()的行为
以下代码示例从名为 file.txt 的文件中读取内容,并将其上传到 GridFS 存储桶。它使用一个 opts 参数来设置文件元数据
file, err := os.Open("path/to/file.txt") uploadOpts := options.GridFSUpload().SetMetadata(bson.D{{"metadata tag", "first"}}) objectID, err := bucket.UploadFromStream("file.txt", io.Reader(file), uploadOpts) if err != nil { panic(err) } fmt.Printf("New file uploaded with ID %s", objectID)
New file uploaded with ID 62e00...
使用输出流上传
要使用输出流上传文件,请使用 OpenUploadStream() 方法,并传入以下参数
您的文件名
一个可选的
opts参数,用于修改OpenUploadStream()的行为
以下代码示例在 GridFS 存储桶上打开一个上传流,并使用 opts 参数设置每个块的字节数。然后,它调用 Write() 方法将 file.txt 的内容写入流
file, err := os.Open("path/to/file.txt") if err != nil { panic(err) } // Defines options that specify configuration information for files // uploaded to the bucket uploadOpts := options.GridFSUpload().SetChunkSizeBytes(200000) // Writes a file to an output stream uploadStream, err := bucket.OpenUploadStream("file.txt", uploadOpts) if err != nil { panic(err) } fileContent, err := io.ReadAll(file) if err != nil { panic(err) } var bytes int if bytes, err = uploadStream.Write(fileContent); err != nil { panic(err) } fmt.Printf("New file uploaded with %d bytes written", bytes) // Calls the Close() method to write file metadata if err := uploadStream.Close(); err != nil { panic(err) }
检索文件信息
您可以从 GridFS 存储桶的 files 集合中检索存储的文件元数据。每个 files 集合中的文档包含以下信息
文件 ID
文件长度
最大块大小
上传日期和时间
文件名
一个可以存储任何其他信息的
metadata文档
要检索文件数据,请在一个 GridFSBucket 实例上调用 Find() 方法。您可以传递一个查询过滤器作为 Find() 的参数,以仅匹配某些文件文档。
注意
《Find()` 方法需要一个查询过滤器作为参数。为了匹配 files 集合中的所有文档,将一个空的查询过滤器传递给 Find()。
以下示例检索 files 集合中长度大于 1500 的文档的文件名和长度。
filter := bson.D{{"length", bson.D{{"$gt", 1500}}}} cursor, err := bucket.Find(filter) if err != nil { panic(err) } type gridfsFile struct { Name string `bson:"filename"` Length int64 `bson:"length"` } var foundFiles []gridfsFile if err = cursor.All(context.TODO(), &foundFiles); err != nil { panic(err) } for _, file := range foundFiles { fmt.Printf("filename: %s, length: %d\n", file.Name, file.Length) }
下载文件
您可以通过以下方式之一下载 GridFS 文件
使用
DownloadToStream()方法将文件下载到输出流。使用
OpenDownloadStream()方法打开输入流。
将文件下载到输出流
您可以使用 DownloadToStream() 方法将 GridFS 存储桶中的文件直接下载到输出流。该方法需要一个文件 ID 和一个 io.Writer 作为参数。该方法将具有指定文件 ID 的文件下载并写入到 io.Writer。
以下示例下载一个文件并将其写入到文件缓冲区
id, err := primitive.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") fileBuffer := bytes.NewBuffer(nil) if _, err := bucket.DownloadToStream(id, fileBuffer); err != nil { panic(err) }
将文件下载到输入流
您可以使用 OpenDownloadStream() 方法,将 GridFS 桶中的文件下载到内存中的输入流。该方法接受一个文件 ID 作为参数,并返回一个您可以从中读取文件的输入流。
以下示例将文件下载到内存并读取其内容
id, err := primitive.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") downloadStream, err := bucket.OpenDownloadStream(id) if err != nil { panic(err) } fileBytes := make([]byte, 1024) if _, err := downloadStream.Read(fileBytes); err != nil { panic(err) }
重命名文件
您可以使用 Rename() 方法更新您桶中 GridFS 文件的名字。将文件 ID 和新的 filename 值作为参数传递给 Rename()。
以下示例将文件重命名为 "mongodbTutorial.zip"
id, err := primitive.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") if err := bucket.Rename(id, "mongodbTutorial.zip"); err != nil { panic(err) }
删除文件
您可以使用 Delete() 方法从您的 GridFS 桶中删除文件。将文件 ID 值作为参数传递给 Delete()。
以下示例删除文件
id, err := primitive.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") if err := bucket.Delete(id); err != nil { panic(err) }
删除 GridFS 存储桶
您可以通过使用 Drop() 方法来删除 GridFS 存储桶。
以下代码示例删除了一个 GridFS 存储桶
if err := bucket.Drop(); err != nil { panic(err) }
其他资源
要了解更多关于 GridFS 及其操作的信息,请访问 GridFS 手册页面。
API 文档
要了解更多关于本指南中讨论的方法或类型的信息,请参阅以下 API 文档