时间序列数据在社会媒体、股票行情和物联网设备等各个领域都有生成。分析时间序列数据使组织能够提前于竞争对手检测、预防和预测事件。但是,日益增长的时间序列数据应该存储在哪里?以及如何进行分析呢?
MongoDB 在 5.0 版本中增加了对时间序列数据的原生支持。在这篇文章中,您将了解时间序列数据是什么,如何在 MongoDB 中存储和查询时间序列数据,以及与 MongoDB 一起处理时间序列数据的最佳实践。
什么是时间序列数据?
时间序列数据是从一个或多个来源在时间间隔内收集的测量值。
虽然并非所有数据都是时间序列数据,但越来越多的数据可以归类为时间序列数据。几乎每个公司都需要查询、分析和报告时间序列数据。考虑一个不断查看股票价格随时间变化的股票交易员,他们运行算法来分析趋势以识别机会。他们查看的时间间隔是每小时或每天。另一个例子可能是连接的气象测量设备如何获取湿度水平和温度变化的遥测数据来预测天气。此外,它还可以监测空气污染,在危机发生之前发出警报或进行分析。可以查看一段时间范围内的收集信息来计算趋势。
以下是一个股票交易测量的单个文档示例
{
date: ISODate("2020-01-03T05:00:00.000Z"),
symbol: 'AAPL',
volume: 146322800,
open: 74.287498,
adjClose: 73.486023,
high: 75.144997,
low: 74.125,
close: 74.357498
}通常,时间序列数据包括时间和测量值,以及其他标识信息,如数据的来源。在这个捕获股票交易信息的时序数据示例中,我们有 日期 作为时间分类器,股票符号作为 标识 字段,而像 开盘价 和 收盘价 这样的信息是本例中的测量值。
MongoDB 中的时间序列数据
当您处理时间序列数据时,您不仅关心存储数据,还需要高读写性能和高级查询功能。MongoDB 是一个基于文档的通用数据库,具有灵活的模式设计和丰富的查询语言。从 MongoDB 5.0 开始,MongoDB 原生支持时间序列数据。
您可以使用 来创建一个新的 createCollection() 命令。当您想要创建一个时间序列集合时,您必须包含 timeField 选项。timeField 指示包含每个文档中日期的字段名称。您还应包括以下选项
metaField指示每个文档中包含元数据的字段名称。metaField 作为标签或标记,允许时间序列集合唯一标识时间序列的来源。此字段在时间上不应或很少改变。granularity字段指示具有匹配的 metaField 的文档之间的时间跨度,如果指定了该字段。默认粒度为"seconds",表示与由 metaField 标识的每个唯一时间序列相关的高频摄取率。粒度可以设置为"seconds,""minutes,"或"hours,"并可以随时修改为更粗糙的粒度。然而,您不能将粒度修改为更细的粒度,例如,从 "minutes" 到 "seconds",因此建议从更细的粒度开始,然后调整为更粗糙的粒度。
最后,如果您想在一定时间后删除数据,您可能希望包括此选项。
expireAfterSeconds字段指示文档在多少秒后过期并被自动删除。
以下示例创建了一个名为 dowJonesTickerData 的时间序列集合,其中 timeField 为 date,metaField 为 symbol。
db.createCollection("dowJonesTickerData",
{ timeseries: {
timeField: "date",
metaField: "symbol",
granularity: "minutes" } })您添加到时间序列集合的每个文档都需要指定至少一个 timeField。在下面的示例文档中,timeField 是 date。请注意,timeField 可以命名为任何名称,只要它是 BSON 类型的 Date。您可以使用插入其他 MongoDB 集合文档的任何方法将文档添加到时间序列集合中。以下示例使用 insertOne() 将文档添加到 dowJonesTickerData 集合。
db.dowJonesTickerData.insertOne({
date: ISODate("2020-01-03T05:00:00.000Z"),
symbol: 'AAPL',
volume: 146322800,
open: 74.287498,
adjClose: 73.486023,
high: 75.144997,
low: 74.125,
close: 74.357498
})插入的每个测量值都应该是单个测量值,无论是单个文档还是每个文档有一个测量的文档批量。MongoDB 会通过按时间优化存储的数据来减少大小占用,并优化时间序列访问模式和写入吞吐量。
如何在 MongoDB 中检索时间序列数据?
时间序列集合中的文档可以像其他 MongoDB 集合中的文档一样进行查询。例如,我们可以在 MongoDB Shell 或 mongosh 中使用 findOne() 查询 dowJonesTickerData 集合中的一个文档。
db.dowJonesTickerData.findOne()MongoDB Shell 将返回一个文档。
{
date: ISODate("2020-01-03T05:00:00.000Z"),
symbol: 'AAPL',
volume: 146322800,
open: 74.287498,
adjClose: 73.486023,
high: 75.144997,
low: 74.125,
close: 74.357498,
_id: ObjectId("60eea26373c4cdcb6356827d")
}MongoDB 优化了数据,因为它按时间顺序存储数据,而不是在常规集合中的 自然顺序。
您可以通过在 metaField 和/或 timeField 上添加 二级索引 来提高查询性能。
db.dowJonesTickerData.createIndex({ symbol : 1, date : 1});如果您想启用多个元数据字段的搜索(例如,符号和公司),我们建议更新您的数据模型。而不是 metaField 是单个值(例如,符号),更新 metaField 为包含多个元数据的项目对象。
例如,让我们删除现有的 dowJonesTickerData 集合并创建一个新的集合,该集合有一个名为 "meta" 的 metaField。
db.dowJonesTickerData.drop();
db.createCollection("dowJonesTickerData",
{ timeseries: {
timeField: "date",
metaField: "meta",
granularity: "minutes" } })接下来,让我们插入一个文档,该文档在 meta 字段中存储多个元数据。
db.dowJonesTickerData.insertOne({
date: ISODate("2021-05-20T10:24:51.303Z"),
meta : { symbol: 'ba', company: 'boeing'},
price: 125
})现在,我们可以创建一个具有多个字段的二级索引。在我们的例子中,我们将创建一个允许高效搜索 symbol 和 company 的二级索引。
db.dowJonesTickerData.createIndex({ "meta.symbol" :1, "meta.company" :1 , date : 1});清理文档
时间序列数据在某个时间后可能不再相关。清除或存档旧数据可以使集合尽可能小,从而提高性能并降低成本。
自动删除时间序列文档
自动删除过期数据的首选方法是在时间序列集合上设置 TTL,即 Time To Live 表达式,以 expireAfterSeconds 参数的形式。数据将在文档日期值达到“now - expireAfterSeconds”后删除。
db.createCollection("dowJonesTickerData",
{ timeseries: {
timeField: "date",
metaField: "meta" ,
granularity : "minutes"
},
expireAfterSeconds : 94608000 // 3 years
})在上面的示例中,当日期字段中存储的值达到三年后,文档将被删除。
您可以在创建集合期间或之后任何时间点设置或修改此参数,因此如果您的数据生命周期要求发生变化,您可以轻松修改或更新数据的生存时间。
在MongoDB中分析时间序列数据
MongoDB提供各种聚合管道运算符和聚合管道阶段,以使开发人员能够分析数据。这些运算符和阶段对所有集合都可用——时间序列或常规集合。让我们检查在5.0版本中添加的一些新运算符和阶段,以使处理日期和时间更容易。
新的聚合管道运算符:$dateAdd、$dateDiff和$dateTrunc
在5.0版本中,MongoDB添加了这些聚合管道运算符
- $dateAdd:向日期对象添加指定的时间量
- $dateDiff:返回两个日期之间的时间差
- $dateTrunc:返回截断到指定单位的日期
这些新运算符使处理时间序列数据变得更加容易。访问官方MongoDB文档中的聚合管道运算符以了解所有可用运算符的更多信息。
$dateTrunc示例
考虑原始股票数据示例
{
date: ISODate("2020-01-03T05:00:00.000Z"),
symbol: 'AAPL',
volume: 146322800,
open: 74.287498,
adjClose: 73.486023,
high: 75.144997,
low: 74.125,
close: 74.357498
}对于此示例,dowJonesTickerData集合使用“date”作为timeField,“symbol”作为metaField。
假设我们想要计算集合中每个股票的平均收盘价。我们可以使用$dateTrunc将日期截断到适当的月份。然后,我们可以使用$group首先按月份和符号对文档进行分组,然后对每个组进行计算。
db.dowJonesTickerData.aggregate([{
$group: {
_id: {
firstDayOfMonth: {
$dateTrunc: {
date: "$date",
unit: "month"
}
},
symbol: "$symbol"
},
avgMonthClose: {
$avg: "$close"
}
}
}])运行上述聚合的结果是一组文档。每个文档包含特定股票每月的平均收盘价。以下是运行上述聚合后生成的示例文档。
{
_id: {
firstDayOfMonth: ISODate("2020-06-01T00:00:00.000Z"),
symbol: 'GOOG'
},
avgMonthClose: 1431.0477184545455
},
{
_id: {
firstDayOfMonth: ISODate("2021-07-01T00:00:00.000Z"),
symbol: 'MDB'
},
avgMonthClose: 352.7314293333333
},
{
_id: {
firstDayOfMonth: ISODate("2021-06-01T00:00:00.000Z"),
symbol: 'MSFT'
},
avgMonthClose: 259.01818086363636
}使用新的聚合管道阶段:$setWindowFields的窗口函数
窗口函数允许开发者在指定窗口内的文档上运行计算。MongoDB在5.0版本中引入了$setWindowFields聚合管道阶段,添加了对窗口函数的支持。类似于$group,$setWindowFields允许你在定义的窗口上应用一个或多个操作。在$group中,文档被分组在一起,然后对每个组进行计算。在$setWindowFields中,窗口相对于每个文档,因此计算是在每个文档上进行的。
使用新的$setWindowFields运算符,你可以计算每个股票过去30天收盘价的滚动平均值。
db.dowJonesTickerData.aggregate( [
{$setWindowFields: {
partitionBy: { symbol : "$symbol" } ,
sortBy: { date: 1 },
output: {
averageMonthClosingPrice: {
$avg : "$close",
window : { range : [-1, "current"], unit : "month" }
} }
} }] )
)运行上述聚合操作的结果是一组文档。该组将包含与原始集合相同数量的文档。结果中的每个文档都将包含一个新的字段:$averageMonthClosingPrice。$averageMonthClosingPrice的值是所指示股票代码上个月收盘价的平均值。以下是运行上述聚合操作后得到的一个示例文档。
{
date: ISODate("2020-01-29T05:00:00.000Z"),
symbol: 'AAPL',
volume: 216229200,
adjClose: 80.014801,
low: 80.345001,
high: 81.962502,
open: 81.112503,
close: 81.084999,
averageMonthClosingPrice: 77.63137520000001
}MongoDB Charts是一个很好的工具,可以可视化上述聚合管道计算出的数据。
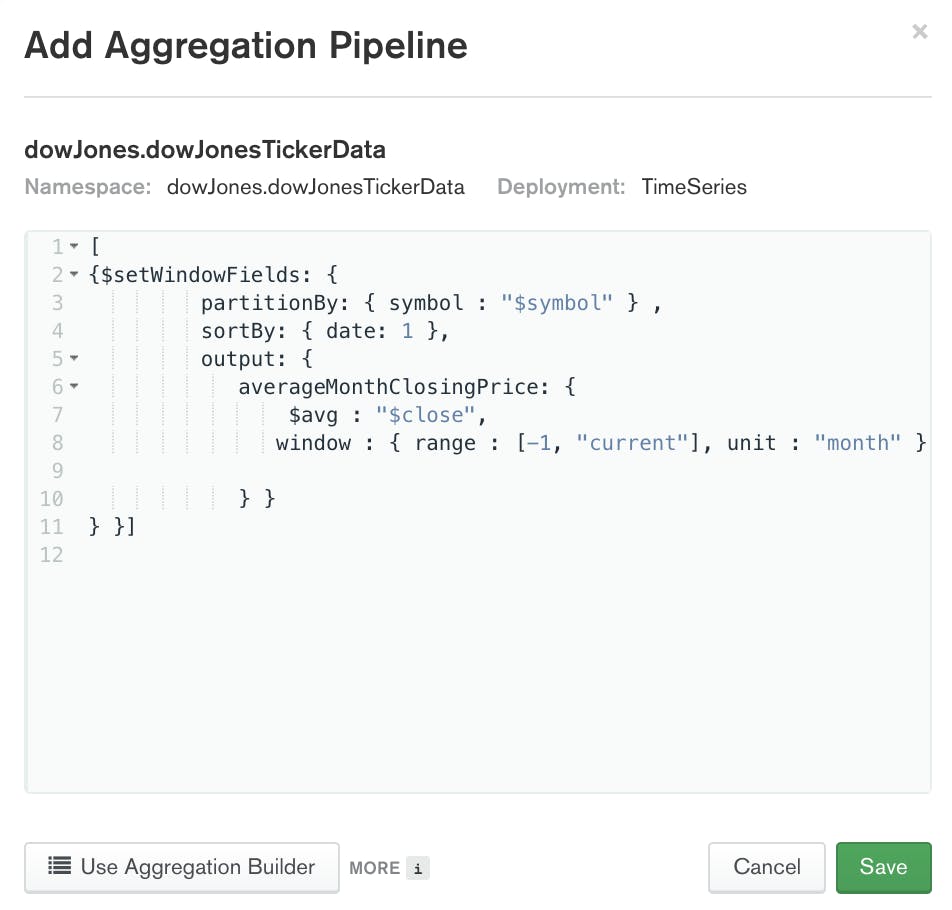
调整图表的数据源,使用我们上面使用的相同管道
[
{$setWindowFields: {
partitionBy: { symbol : "$symbol" } ,
sortBy: { date: 1 },
output: {
averageMonthClosingPrice: {
$avg : "$close",
window : { range : [-1, "current"], unit : "month" }
} }
} }]
因此,数据源公开了所有字段,例如symbol、date、close和averageMonthClosingPrice,可以直接在折线图中使用
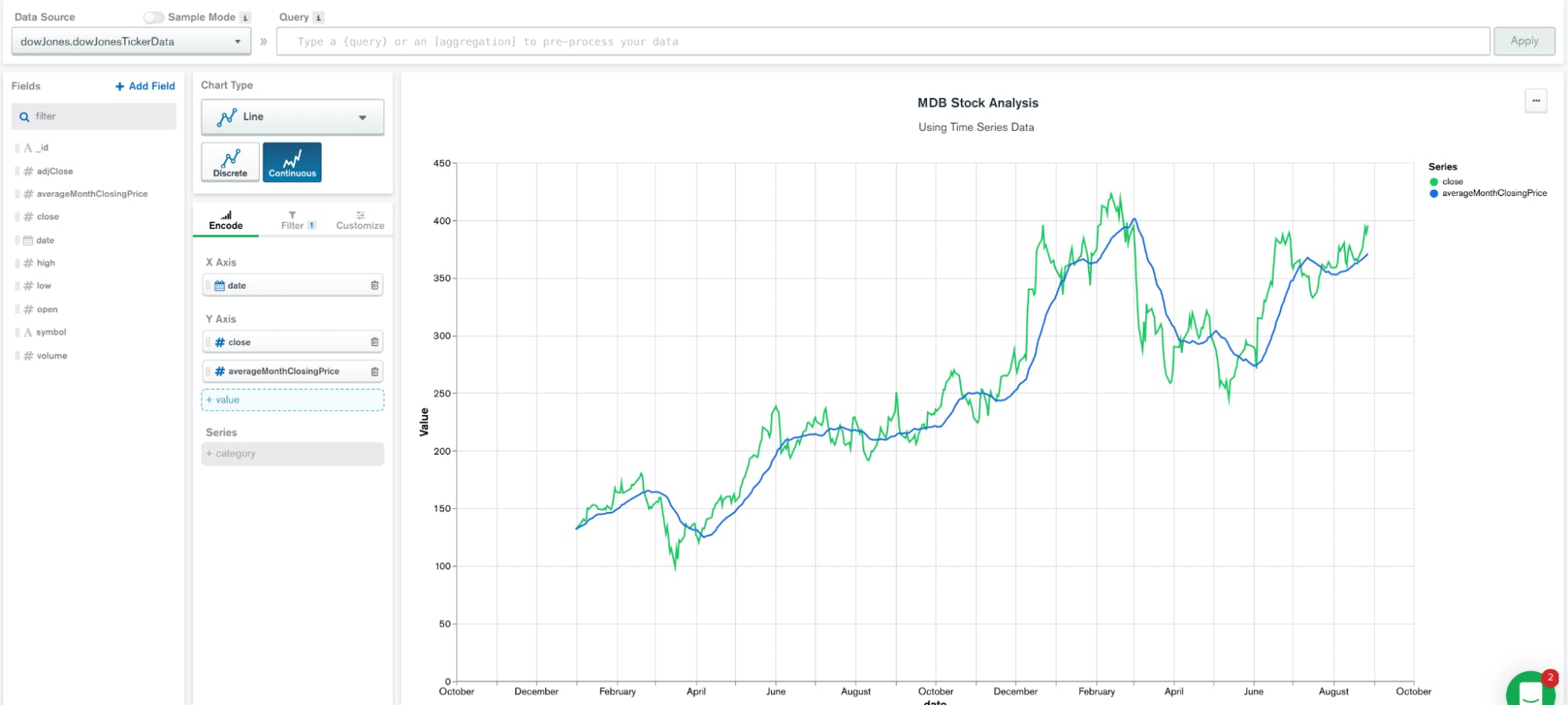
在绘制这些数据时,我们可以看到此分析的价值
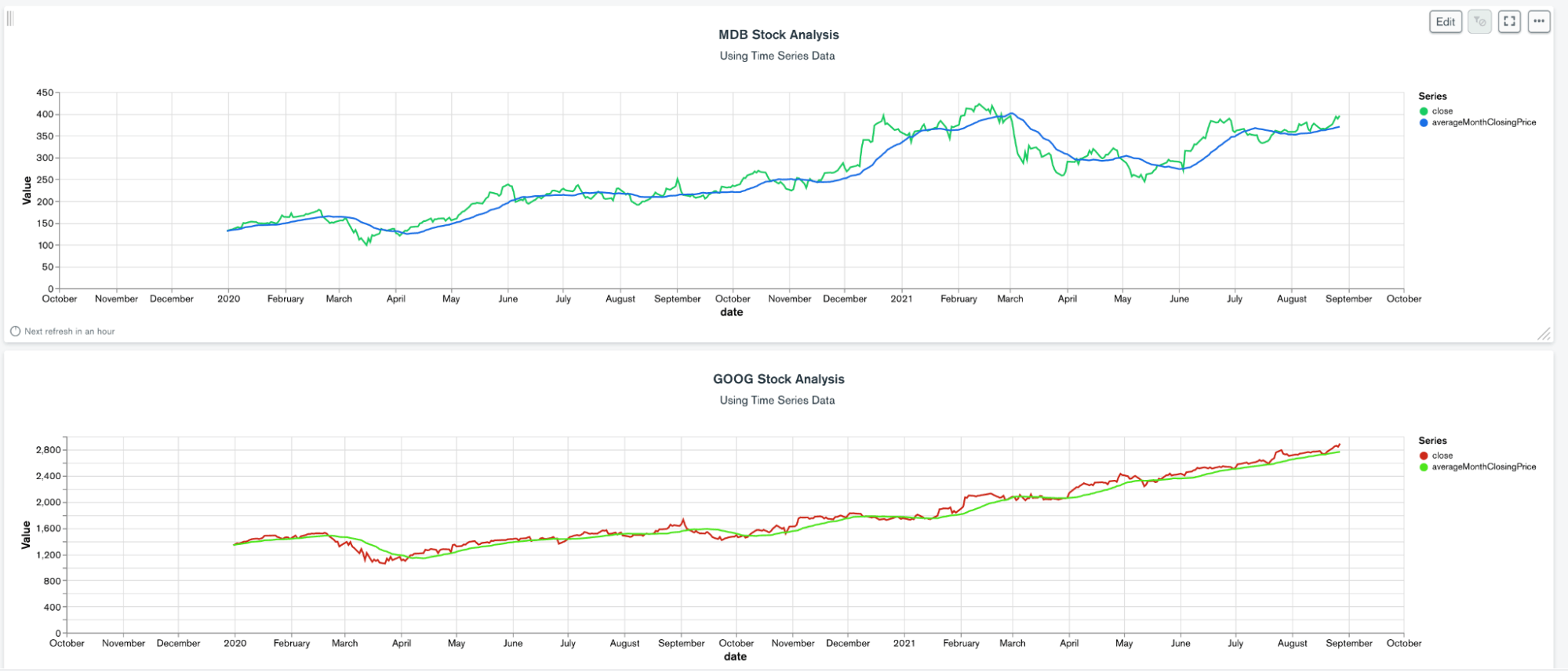
上面的图表显示了每个股票的收盘价和滚动30天平均图。
MongoDB中存储时间序列数据的最佳实践
以下是MongoDB中处理时间序列数据六个最佳实践的列表
- 尽可能使用带时间序列数据的时间序列集合。
- 在使用时间序列集合时,将单个测量值或测量值组作为一批插入的单个文档存储。
- 根据数据特性和查询模式调整数据,以具有适当的metaField和timeField。
- 根据与您的metaField基数或唯一metaField的唯一组合相关的数据摄入率调整数据粒度。例如,如果您的metaField是customerId,但您每五分钟只从唯一的customerId接收数据,那么尽管您可能每分钟总共接收10k个插入,您应该将粒度更改为分钟。对于metaField值的峰值数据是可接受的。这不需要是均匀的,但应该是尽可能好的近似。
- 确认您了解当前时间序列集合的限制。
总结
时间序列数据无处不在,但存储和查询它可能具有挑战性。MongoDB在5.0版本中添加了对时间序列数据的原生支持,这使得处理时间序列数据更加容易、更快、更便宜。
亲自尝试。
在MongoDB Atlas上开始处理时间序列数据。
常见问题解答(FAQ)
什么是时间序列数据?
时间序列数据是从一个或多个来源在时间间隔内进行的测量。当分析时,个别数据点在一段时间内形成有意义的洞察。例如,天气测量数据和股票交易数据。
MongoDB 是时序数据库吗?
MongoDB 是一种通用文档数据库,它原生支持时序数据。MongoDB 的 时序集合 经过优化,专为处理、存储和查询时序数据而设计。因此,用户可以使用统一的查询 API,将 MongoDB 作为时序数据库与其他数据库用途一起使用。