全球生成的数据量呈几何级数增长,这已不是秘密。实际上,预计到2025年底,将首次出现181泽字节的数据(为了说明,一个泽字节等于一十六亿字节)!在这些181泽字节中,80%的数据预计将是非结构化数据。
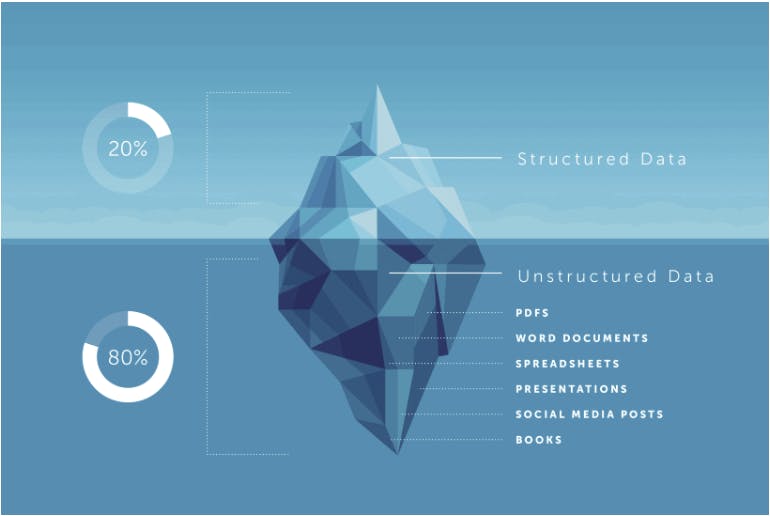 (来源:K21Academy.com,2023)
(来源:K21Academy.com,2023)
然而,这也突显了所有类型数据用户的一个重大问题。非结构化数据,特别是非结构化文本数据,既不能存储在也不能由传统的关系型数据库进行查询。此外,传统的查询只搜索精确文本匹配,这对用户帮助不大,因为用户通常只知道他们在文本数据中搜索的主题或关键思想。
解决这个问题的是全文搜索。全文搜索使用户能够以直观和高效的方式访问其非结构化文本数据,同时这些数据以最佳方式存储在非关系型、NoSQL数据库中。继续阅读,了解全文搜索是什么,它是如何工作的,以及它的应用实例。
目录
什么是全文搜索?
与依赖于精确单词或短语匹配的传统搜索方法不同,全文搜索是指在全文本查询范围内的所有相关文档内容中的搜索。这包括主题、措辞、引用或额外的文本属性。
全文搜索的类型
有各种方法可以进行全文搜索。每种类型都有自己的优点,就像工具箱中的工具一样,旨在解决特定的需求。以下是其中一些最常见类型:
简单全文搜索:简单全文搜索非常基础,用户输入关键词或短语以找到包含这些特定术语的文档。
- 最佳用途:这些搜索通常用于快速搜索以获取一般信息。
布尔全文搜索:此类搜索使用布尔运算符(例如,AND、OR、NOT)来组合或排除搜索查询中的特定关键词。这不仅提供了对搜索结果的更多控制,还有助于用户将广泛的主题缩小到他们所寻求的特定信息。
- 最佳用法:常用于复杂查询,使用术语之间的逻辑关系,布尔全文搜索有助于用户节省时间并提高查询的相关性。
模糊搜索:模糊搜索允许用户找到“可能”匹配的文本,这意味着在所需术语中的拼写错误、打字错误等可以被分析为匹配用户参数。
- 最佳用法:这些搜索在搜索经常有非传统拼写、打字错误或其他不规则性的文档时很有帮助。
通配符搜索:通配符搜索包含非字母数字字符(例如,?、*),代表单词未知部分。这使用户能够搜索单词的不同形式(例如,part、parted、parting)或部分匹配(例如,summertime、summer vacation、summer)。
- 最佳用法:这些搜索在用户想要考虑单词的不同形式或正确的拼写变体时很有帮助。
短语搜索:此搜索寻求一个确切的短语,其中短语查询中的单词按指定顺序出现在文档中。
- 最佳用法:短语搜索常用于在长文档中搜索与上下文相关的术语的查询(例如,在IRS网站上搜索“2024年所得税率”)。
邻近搜索:邻近搜索确定并检索包含特定术语的文档,这些术语彼此之间的单词、短语或段落数量是一定的。
- 最佳用法:邻近搜索在搜索广泛主题的长文档时很有用。例如,一本关于海洋保护的专著可能包括关于所有类型的海洋环境(例如,深海、河口、红树林)的信息,但通过使用邻近搜索索引查找红树林保护信息时,大多数相关的红树林信息将从文档中检索出来。
范围搜索:范围搜索查找用户指定的数值或字母范围内的术语。
- 最佳用法:当用户对日期、货币价值或字母数字医学编码等范围感兴趣时,范围搜索很有帮助。
分面搜索:此类搜索有助于使用预定义的分类和主题的特定属性(例如,分面)来细化结果。
- 最佳用法:这些搜索在日常电子商务中使用(例如,中号、棉质、衬衫领、蓝色、衬衫)。描述符或属性——如中号、蓝色和衬衫——都是用户想要的衣服的方面。
全文搜索查询
全文查询用于全文搜索中,以定义用户所需的具体术语、参数等。此外,全文查询通过以下多种方法,包括以下方法,使用户发现他们可能未知的内容:
自然语言处理(NLP):全文搜索通常结合自然语言处理技术来理解全文查询中的单词和文档中的文本的上下文、语义和关系。这提供了准确且与上下文相关的结果,即使用户不知道他们应该在全文搜索查询中包含哪些特定术语或短语。
同义词扩展:全文搜索引擎通常采用同义词扩展功能。这意味着全文搜索引擎能够识别与用户查询中包含的词语或短语具有相同意义(例如,同义词)的替代词语或短语。鉴于这种相关搜索词的扩展,即使用户在初始全文查询中没有包含这些特定的词语(例如,同义词),也能为用户收集到更多相关信息。
本体和分类法:使用本体或分类法有助于根据词语关系将术语分组到层次结构中。利用这些层次结构,全文搜索得到增强,可以返回与用户查询相关的更广泛和更狭窄的术语。这提供了一个准确且更全面的搜索结果集。
模糊匹配:模糊匹配算法使数据库引擎能够找到查询的近似搜索词匹配。这意味着含有错别字、漏掉的拼写错误或其他实际与查询匹配但传统搜索会忽略的语言变体,都会被识别并收集给用户。
相关性排序:在相关性排序中,采用复杂算法考虑诸如术语使用频率和术语在文档中的邻近度等因素,以帮助识别可能包含与用户查询相关但意外的非常相关信息的相关文档。
这些技术的组合增强了全文搜索系统发现相关信息的能力,使其成为非结构化文本数据探索和发现的有力工具——即使用户可能没有完全了解他们正在研究的主题的广度和深度。
全文搜索索引
全文搜索涉及审查大量文档和大量文本。网络搜索服务通常使用全文搜索从互联网检索相关结果——无论是网页内容、在线PDF文件等。鉴于涉及到的文本数据量,需要一种处理搜索流量的技术——它被称为全文索引。全文搜索索引是一种专门的数据结构,能够快速、高效地搜索大量文本数据。
创建全文搜索索引时,会分析数据集(例如,文档)的每个文本字段。首先,删除重音符号(放置在字母上方或下方的标记,如法语中的é、à和ç)。然后,根据文本所使用的语言,算法会删除填充词并仅保留术语的词干。这样,“to eat”和“eating”被分类为同一根词:“eat”。
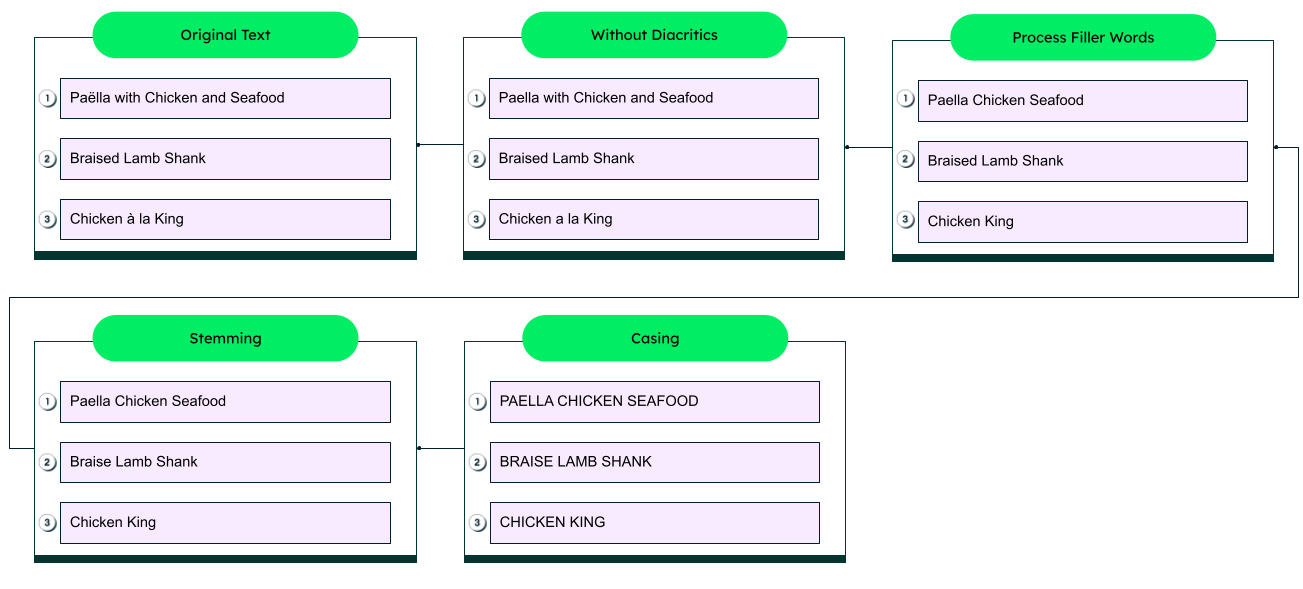
接下来,将所有文本转换为全大写或全小写文本。根据开发全文索引所使用的特定分析器,还可能包括其他步骤。
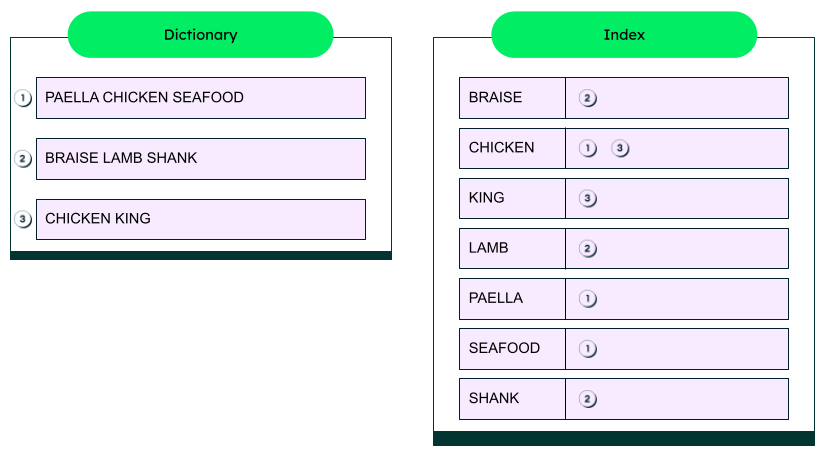
最后,创建索引,存储每个术语(例如,单词、短语)在文档中可找到的位置的引用。
全文索引特征概述
将术语映射到文档:全文索引的主要功能是将术语(例如,单词、短语、数字)映射回包含它们的文档。在创建索引的过程中,审查文档内容并创建术语与其相应文档之间的链接。
增强查询速度:一旦创建全文索引,它允许快速查找和检索与用户搜索查询相关的文档。而不是扫描每个文档或所有网页的全部内容,搜索引擎可以通过查阅索引快速识别包含指定术语的文档。
优化:除了增强查询速度外,还应用了额外的优化措施以提高索引速度和存储效率。数据缓存、数据压缩以及其他数据结构优化通常被采用,以创建一流的全文搜索系统。
全文索引类型
有各种全文索引类型可供选择。用户在选择全文索引方法时,搜索需求、数据类型和体积以及查询复杂性是关键考虑因素。此外,一些用户可能选择采用多种索引方法以优化性能并解决数据存储问题。两种常见的全文索引包括倒排索引和B树索引。
倒排索引:倒排索引是最常用的。这些索引存储了术语与包含它们的文档之间的映射。它们在搜索过程中启用快速查找(即,搜索索引而不是所有文档)并优化搜索过程。
在倒排索引中,一些后台发生的附加功能包括
压缩:应用数据压缩技术以减少索引数据存储需求。
定位:包含所选术语的位置的附加信息被包含在内,从而实现邻近度和短语查询。
频率:不是映射术语,而是映射文档。这在分析术语在文档中出现的次数时很有用。
N元组:文本被分解为N元组(即,字符或单词的连续序列)。例如,短语“The slow tortoise beat the lazy hare”可以分解为N-1,“Tortoise beat the lazy hare”;N-2,“The slow tortoise beats”;N-3,“Tortoise beats the lazy”;等等。N元组索引可以实现部分匹配和通配符查询。
B树和B+树:当全文搜索集成到关系数据库中时,通常使用B树和B+树。具体来说,它们通常用于范围查询(例如,日期范围、货币值范围)。
全文搜索示例
全文搜索有许多不同的用途。例如,倒排索引可用于在餐厅菜单中查找菜肴或在电子商务网站上商品描述中查找特定功能。除了搜索特定关键词外,全文搜索还可以通过模糊文本和同义词等搜索功能进行增强。在我们的示例中,“pasta”等单词的结果将不仅返回“Pasta with meatballs”等商品,还可以通过同义词返回“Linguine Carbonara”或通过模糊搜索返回“Psta”。
在开源搜索库Apache Lucene的示例中,它使用倒排索引来定位餐厅菜单项,并充当任何匹配文档的广泛词汇表。
您可以在https://www.atlassearchrestaurants.com/找到类似的全功能菜单项全文搜索演示。
在SQL中实现全文搜索
要在SQL数据库中实现我们的餐厅菜单全文搜索示例,必须为要索引的每个列创建全文索引。在MySQL中,这将使用FULLTEXT关键字完成。
然后,您可以使用MATCH和AGAINST查询数据库。
ALTER TABLE menus ADD FULLTEXT(item);
SELECT * FROM menus WHERE MATCH(item) AGAINST("pasta");虽然此索引会增加您的查询速度,但它并不提供您可能期望的所有附加功能。要使用模糊搜索、错别字容忍度或同义词等特性,您需要在数据库之上添加Apache Lucene等核心搜索引擎。
在MongoDB Atlas中实现全文搜索示例
在MongoDB Atlas中实现全文搜索引擎只需点击一个按钮。用户前往任何集群,选择“搜索”标签页。然后,点击“创建搜索索引”以启动此过程。
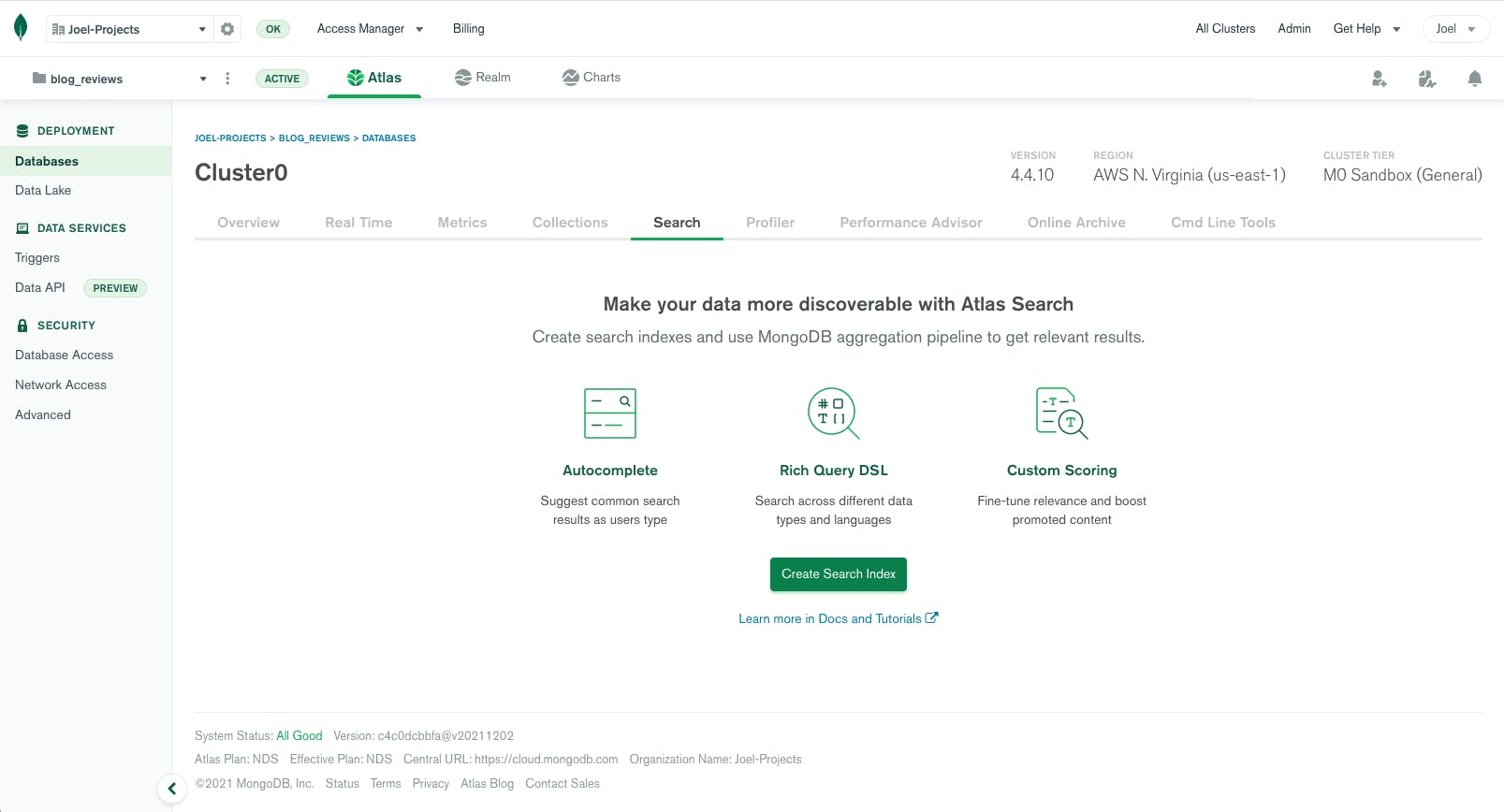
索引创建完成后,您可以使用$搜索运算符执行全文搜索。
db.menus.aggregate([
{
$search: {
text: {
query: "pasta",
path:"item"
}
}
}
]);此聚合操作是MongoDB Atlas Search中最简单的查询。丰富的查询,包括错别字容错、搜索词高亮显示和同义词搜索等,也可以构建。幕后,Atlas Search使用Apache Lucene,因此您无需自己添加引擎。
如果您还没有MongoDB Atlas账户,现在就可以免费注册一个。一旦您设置了账户,您将能够在Atlas Search餐厅搜索器的演示中尝试Atlas Search,或者您可以通过我们的教程了解如何实现它,教程链接为如何构建电影搜索应用程序。
使用全文搜索时的注意事项
在实现全文搜索解决方案之前,考虑必要的功能、架构复杂性和与全文搜索相关的成本是很重要的。在此,我们将使用来自MongoDB Atlas Search的示例来阐述每个考虑因素。
必要功能
将全文索引添加到您的数据库将有助于优化您的文本搜索并可能最小化存储需求。但是,您可能还需要额外的功能,例如自动补全建议、同义词搜索或针对相关结果的自定义评分。MongoDB Atlas Search的一些示例包括
丰富的查询能力:使用广泛的各种运算符,Atlas Search不仅可以搜索文本,还可以搜索地理点和日期。
模糊搜索:用户在输入时有时会犯错。使用Atlas Search的错别字容错,即使有拼写错误,也可以提供准确的结果。
同义词:您的数据可能使用与您的用户搜索不同的措辞。您可以使用同义词来定义等效单词的列表,以向用户提供更相关的结果。
自定义评分:如果您推广了内容或有根据不同变量(例如,在不同时间)更相关的内容,您可以在自定义评分函数中定义它。此分数将帮助将优先结果推送到搜索结果顶部。
自动补全:为用户提供建议,以使他们在输入时获得更流畅的体验。
重点:当搜索结果从您的数据库返回时,将它们自动突出显示搜索词,以帮助您的用户在结果中找到更多上下文。
想了解更多吗?您可以查看MongoDB Atlas Search的所有功能列表。
架构复杂性
添加额外的组件会增加您应用程序的复杂性。为了向您的应用程序提供全文搜索功能,您需要一个额外的层来处理索引并提供结果。
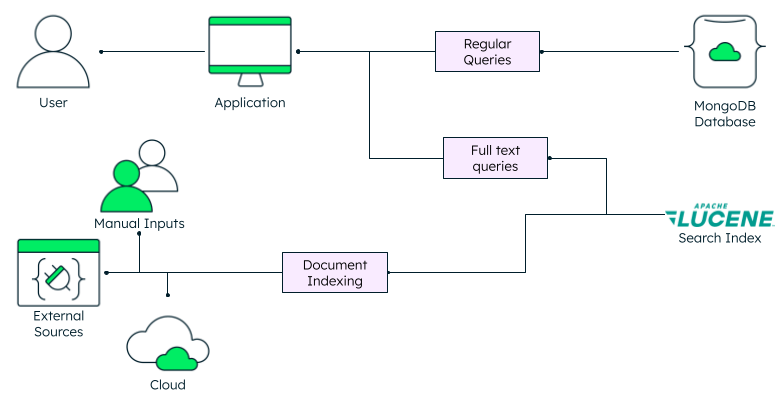
使用MongoDB Atlas Search,所有功能都集成到您的数据库中。软件开发人员无需担心在哪里查询——他们可以使用常规的聚合管道访问数据,就像使用传统数据一样。
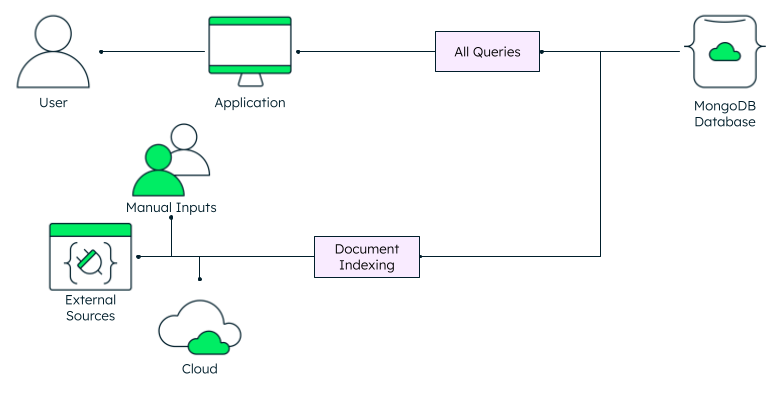
通过去除这个额外的层,软件开发简化了,同时避免了在架构中实现和维护不同组件的相关开销。
成本
无论解决方案是在内部构建还是使用第三方工具,都应预期会有额外成本。一方面,在内部开发解决方案可能会在开发时间、错误和总体时间上产生高昂的成本。另一方面,即使是开源解决方案,在集成和维护等方面也需要付出代价。这就是为什么许多软件开发团队开始使用现成的解决方案,这些解决方案需要最少的实施和维护工作量。第三方解决方案的固定成本,加上固定的交付时间表,可能是最合理的。在评估适合您的全文搜索解决方案时,请务必考虑所有这些因素。
使用MongoDB Atlas Search之类的解决方案可以通过去除底层基础设施维护和相关的培训来降低成本。它还使得加速开发团队变得更容易,因为大多数团队已经熟悉使用MongoDB查询他们的数据。
了解更多
您准备好发现如何加速全文搜索了吗?以下是一些额外的资源,可以帮助您了解更多。
常见问题解答
什么是全文搜索?
全文搜索有哪些不同类型?
- 简单全文搜索
- 布尔全文搜索
- 模糊搜索
- 通配符搜索
- 短语搜索
- 邻近搜索
- 范围搜索
- 分面搜索
什么是全文搜索查询?
全文查询用于全文搜索中,以定义用户所需的特定术语、参数等。
全文搜索查询有哪些不同类型?
- 自然语言处理(NLP)
- 同义词扩展
- 本体和分类法
- 模糊匹配
- 相关性排名
什么是全文搜索索引?
全文索引有哪些特点?
- 将术语映射到文档
- 增强查询速度
- 资源和存储优化
最常见的全文索引类型有哪些?
- 倒排索引
- B树和B+树
全文搜索是如何工作的?
使用全文搜索时有哪些关键考虑因素?
- 必要功能
- 架构复杂性
- 成本