想象一下您城市的电网。它为该地区的所有家庭和企业提供电力,对每个人来说都是必不可少的。现在,假设一个社区的变压器出现故障并暂时离线。理想情况下,电网可以从其他来源重新分配电力以补偿故障。这确保了所有家庭和企业继续不间断地接收电力。
这个类比帮助我们理解高可用性(HA)的概念以及为什么它在保持系统或应用程序平稳运行方面如此重要。
让我们讨论一下什么是高可用性,为什么需要备份操作模式,以及如何开始衡量您关键系统的可用性。
目录
高可用性的定义
让我们从最基本的问题开始:什么是高可用性?高可用性意味着我们消除了单点故障,这样,如果这些组件中的任何一个出现故障,应用程序或系统可以继续按预期运行。
换句话说,由于这种故障,系统停机时间将尽可能短——在一个完美的世界里,停机时间为零。
事实上,这个概念通常使用一个称为“五九标准”的标准来表达,这意味着99.999%的时间里,系统按预期工作。这是我们(雄心勃勃的)追求的可用性标准。
然而,值得注意的是,一些公司可能有不同的可用性目标,如四九(99.99%)、三九(99.9%)和二九(99%)。这些级别代表不同的可用性承诺水平。
实现这一目标的要素
高可用性的两个重要方面是(1)数据故障转移系统和(2)数据备份。为了实现高可用性,系统必须有一种方式来维持其功能——例如,通过存储数据——当事情没有按计划进行时。
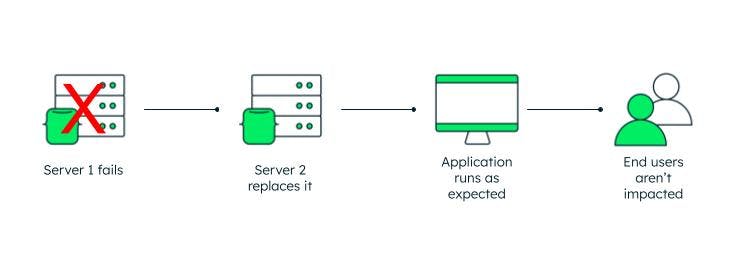
在我们之前提供的例子中,单点故障是出现故障的变压器。城市(希望)通过另一个可以无缝接替的变压器为此做好了准备。
您可能能够与之相关的一些其他单点故障的例子包括常规服务器维护、网络故障、硬件故障、软件故障,甚至是自然灾害造成的停电。
所有这些都可能导致服务中断并损害系统性能,有时甚至非常严重。
关于高可用性集群呢?
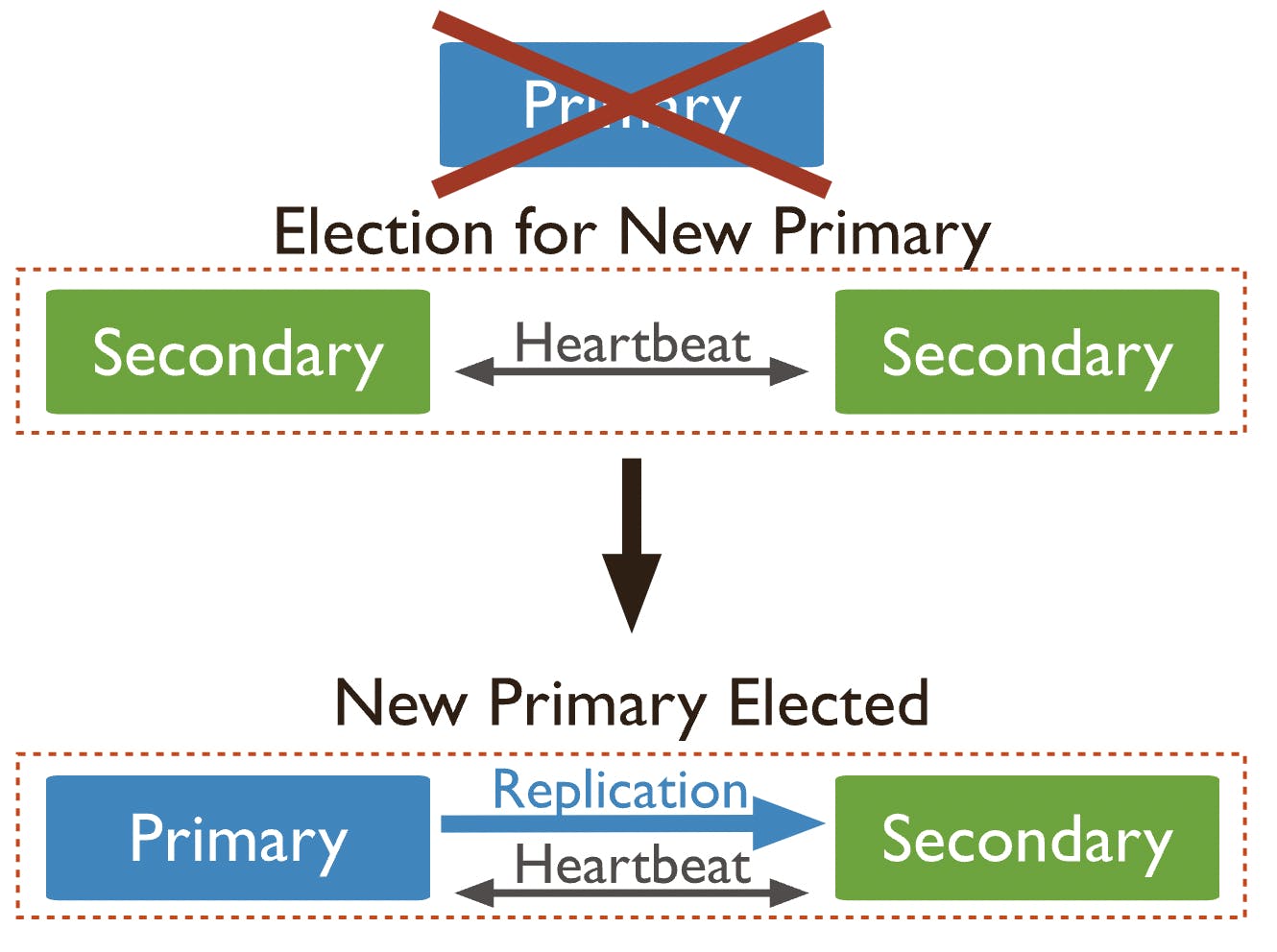
我们还可以更具体地谈谈高可用性集群,它们是一组作为单个系统一起工作的服务器。虽然这些服务器共享存储,但它们位于不同的网络中。
高可用性集群具有故障转移功能,这意味着如果其中一台服务器出现故障,将有一个备份组件可以取代它。
容错性
当人们谈论高可用性时,你也可能会听到“容错性”被互换使用。本质上,它们指的是同一个概念。
容错性意味着如果系统中的一个或多个组件出现故障,将有一个备份组件准备自动接管,确保系统可以保持连续的可用性,使用户的访问保持稳定,不受干扰。
容错系统中的备份组件可以包括硬件、软件或电源等替代方案。
为什么高可用性很重要?
消除单点故障、实现高可用性和容错性之所以如此重要,是因为这确保了系统能够在不受干扰的情况下连续为最终用户提供服务。它是公司更广泛的灾难恢复协议的一部分,该协议定义了他们在重大停机事件中如何计划将停机和损失降到最低。
事实上,拥有高可用性应该意味着您几乎可以完全避免停机时间,因此不需要灾难恢复。
"嗯,所有系统在某个时刻都会经历停机,对吧?"也许吧,但关键是一些公司根本无法容忍这种情况发生。
高可用性不仅仅在于提供良好的用户体验,防止生产力损失,以及保护品牌声誉。它是对潜在灾难的关键防御。
高可用性系统的例子
想象一下,在电动汽车中使用自动驾驶模式,由于一个故障点,整个系统突然关闭。换句话说,那辆以前在高速公路上以80英里每小时行驶的车突然失去了所有控制。你愿意和这样的司机一起在道路上行驶,还是自己开车?
这听起来可能是一个极端的例子(尽管这是完全可行的)。然而,一些行业依赖高可用性系统来保护他们的数据——以及这些数据属于的人。
想想电子健康记录(EHRs)——包含所有关于患者的信息的实时、数字化记录,这些信息是他们医疗保健提供者想要跟踪的。我们谈论的是他们的诊断、医疗史、处方、疫苗接种,等等。
如果这些EHRs不是建立在高可用性架构之上,并且出现某种系统故障,我们可能会看到大量数据丢失,最坏的情况是,那些极其敏感的数据可能会泄露。
这强调了与高可用性基础设施合作以维护关键数据完整性和安全性的关键重要性。
高可用性的工作原理
实际上,没有任何系统可以在所有时候都实现100%的可用性。然而,为了实现五九法则并构建高可用性系统,我们必须优先考虑高可用性的四个关键支柱。
1. 消除单点故障
正如我们之前提到的,消除单点故障是高可用性系统中的关键。如果没有这种保护措施,如果一切都在一台服务器上运行,而该服务器出现故障,整个系统就会崩溃。
2. 实施可靠的冗余
"冗余"意味着在HA系统中拥有备用组件。这样,如果原始组件出现故障,它的“双胞胎”可以接管它,帮助最大限度地减少因故障而造成的停机时间,并保持高可用性。
3. 促进系统故障检测
在主系统中某个组件发生故障的情况下,应该有明确的协议,以便(1)故障明显并得到记录,并且(2)理想情况下,组件可以自行解决问题。这是灾难恢复的一个重要部分。
4. 实现负载均衡
负载均衡意味着以有效的方式将工作负载——如网络流量——分配到多个系统或服务器。负载均衡器应该能够确定这样做最有效的方法。有了负载均衡,没有任何资源或服务器会因工作负载而超负荷,高可用性变得更加可行。
负载均衡器将根据多个算法来完成这项工作。

这四个元素对于维护高可用性都是必要的。
如何衡量高可用性
如果你无法跟踪和衡量它,那么你就不知道它是否在起作用。那么,你如何衡量可用性呢?
答案并不完全明确,但五九法则是一个良好的起点。随着公司努力在99.999%的时间内保持上线、运行和可用,这已经成为高可用性行业标准,许多复杂系统都是以此为基础进行比较的。
然而,在衡量高可用性架构时,我们必须比这更具体。例如,你是否希望每天24小时,每年365天都能达到99.999%的服务可用性?或者,高可用性只有在你的办公时间内才真正重要?
一点数学
如果您打算在全年 24/7/365 的时间内保持高达 99.999% 的高可用性,那么每年的最大停机时间将不超过 5.256 分钟。
我们是如何到达这个地步的
- 一年中有 60 分钟/小时 x 24 小时/天 x 365 天/年 = 525,600 分钟/年
- 99.999% = 0.99999
- 0.99999 x 525,600 分钟 = 525,594.744 分钟
- 525,600 分钟 - 525,594.744 分钟 = 5.256 分钟
现在,如果您更关心在运营时间内保持高可用性,您期望的最大停机时间数字将有所不同!
可用性测量可能非常复杂,但它主要取决于确定您所追求的最大可用性以及何时对高可用性解决方案有最严格的要求。
何时高可用性最重要?
我们可以将高可用性的测量再向前迈进一步。即使您的目标是全天候 24/7/365 维护峰值运营性能,我们猜测在大多数应用程序中,您会经历用户活动的变化。
也许您在周一早晨看到更高的流量,然后在周末大幅下降。您是否仍然要追求全天候 99.999% 的高可用性,还是对于低流量时段,99.95% 左右的可用性就足够了?
这些数字可能看起来并不那么不同,但如果您进行计算,确实会改变您对“高可用性”(HA)的定义以及您的运营性能目标。
常见问题解答
什么是高可用性?
高可用性意味着消除了故障点,因此如果其中任何一个组件出现故障,应用程序或系统可以继续按预期运行。
什么是高可用性集群?
高可用性集群是作为单个系统一起工作的服务器组。尽管这些服务器共享存储,但它们在不同的网络上。
高可用性是如何工作的?
高可用性需要消除故障点,通过组件的复制建立可靠的冗余,实施便于检测和解决系统故障的机制,并使用负载均衡器高效地在系统或服务器之间路由流量。