分布式数据库的概念被引入,以处理跨机器的大量数据。垂直扩展——即向现有资源添加更多容量——是有限的,因为资源的容量无法超过某个限制。然而,数据增长速度更快,传统的系统无法有效地存储和检索数据。
因此,我们有了分片!
目录
什么是 MongoDB 分片?
分片涉及将数据分布到多台机器上。MongoDB 使用分片来处理涉及大量数据和高性能操作的应用部署。
水平扩展,也称为横向扩展,指的是添加机器以共享数据集和负载。水平扩展允许近乎无限的扩展,以处理大数据和密集型工作负载。
为什么要分片?
在 MongoDB 中,当没有单个服务器可以处理大型现代工作负载时,分片非常有用。它允许您水平扩展整个数据库。由于数字化,对捕获数据的需求不断增长,这给数据库带来了更大的负载。早期系统通常通过向现有资源添加更多容量来增加能力,即垂直扩展。然而,所有资源(内存、磁盘、CPU)都有饱和点,在此之后它们无法处理更多请求,系统响应时间将增加,从而影响系统稳定性和性能。添加更多容量会增加成本,并增加创建/恢复备份所需的时间。
分片遵循无共享架构,这是一种分布式计算架构,其中没有任何节点之间共享任何资源。分片集群将数据分割成多个分片(或分区),每个分片都是一个副本集,即具有主节点和一个或多个辅助节点,用于数据冗余和可用性。根据工作负载,可以添加或删除分区。每个分片负责处理特定请求(工作负载)。
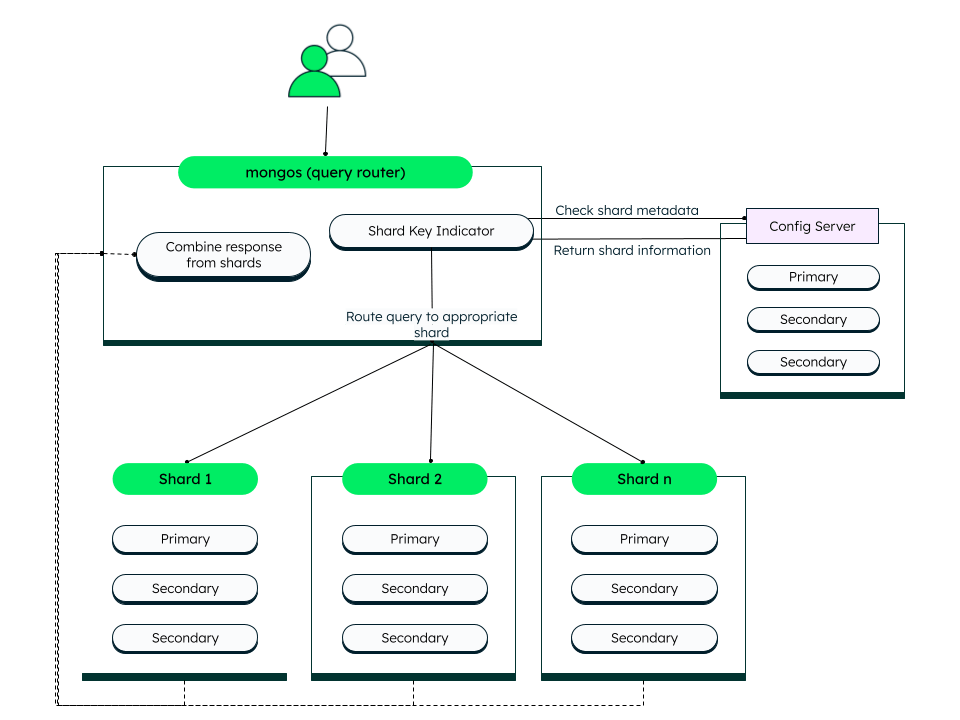
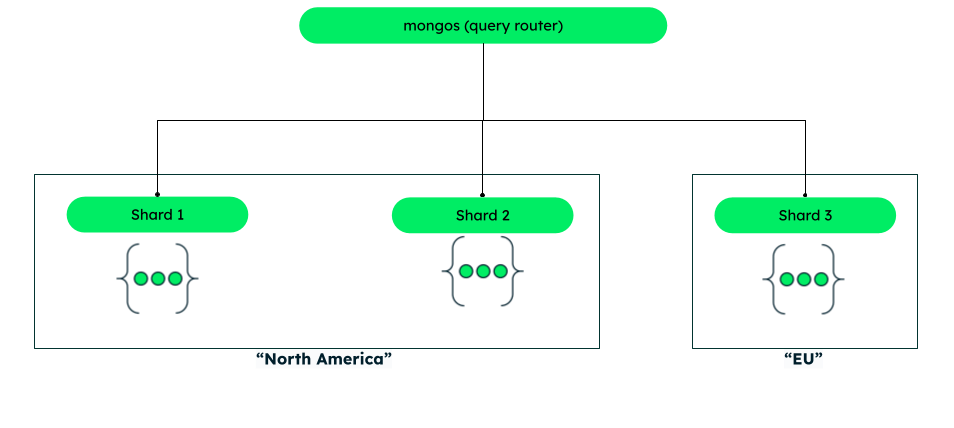
分片集群架构
在 MongoDB 中,一个分片集群由以下部分组成:
- 分片。
- Mongos 实例。
- 配置服务器副本集。
分片
分片是包含集群数据子集的副本集。一旦启用分片,这通常发生在单个MongoDB实例无法处理大量数据集时,MongoDB会将所需的集合分割成多个分片以实现水平扩展。每个分片都有一个主分片和一个或多个副分片。主分片负责写入并同步到副分片。
Mongos实例
Mongos实例作为客户端应用程序的查询路由器,处理读取和写入操作。它将客户端请求分配给相关分片,并将分片的结果聚合为一致的客户端响应。客户端连接到mongos,而不是连接到单个分片。
配置服务器副本集
配置服务器副本集由多个MongoDB副本集成员组成。它们是分片元数据的权威来源。分片元数据反映了分片数据的状况和组织。元数据包含分片集合列表、路由信息等。
分片集群将看起来像这样
MongoDB 分片的优势
MongoDB分片允许您的数据库进行水平扩展,以处理增加的负载,几乎无限地增加读写吞吐量和存储容量。让我们更详细地看看这些。
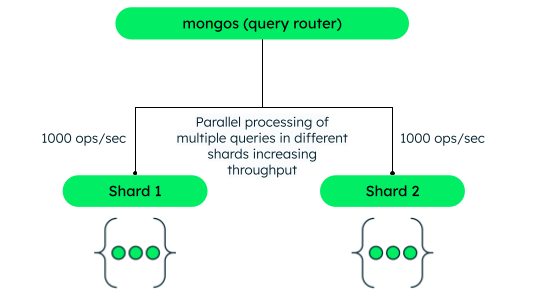
增加读写吞吐量
您可以通过将数据集分布在多个分片上利用并行性。假设一个分片每秒可以处理1,000个操作。对于每个额外的分片,您会额外获得每秒1,000个操作吞吐量。
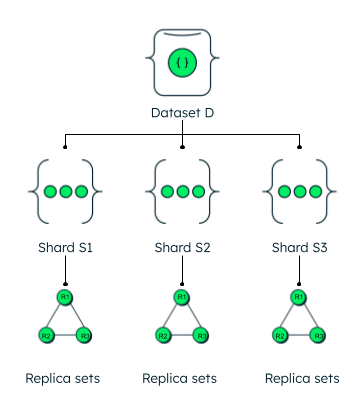
高可用性
分片需要使用副本集。通过利用多个可用服务器,副本集增强了可用性。例如,数据集D被分为3个子集或分片,分布在多个服务器S1、S2和S3上。为了确保高数据可用性和冗余,每个分片都有一个或多个副本,R1、R2、R3。
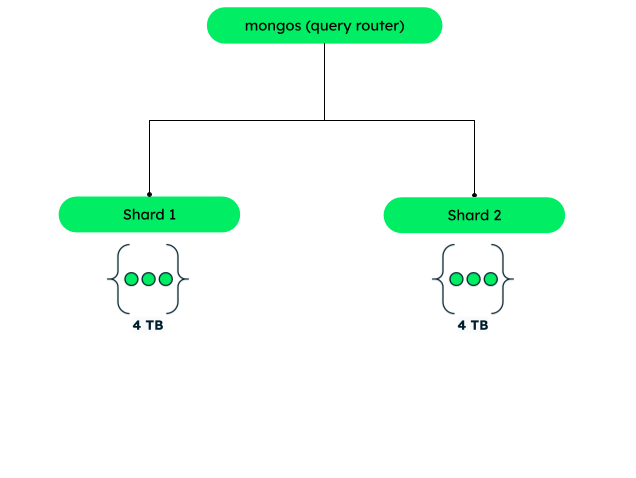
增加存储容量
同样,通过增加分片数量,您也可以增加整体的总存储容量。假设一个分片可以存储4TB的数据。每个额外的分片会增加您总存储4TB。这允许几乎无限的存储容量。
数据分布
分片键
MongoDB在集合级别进行分片。您选择您想要分片的集合。MongoDB使用分片键将集合的文档分布在分片上。MongoDB通过将分片键值的范围划分为非重叠范围来分割数据,创建数据块。每个数据块的最大限制是128MB。然后MongoDB试图将这些数据块在集群中的分片之间均匀分布。
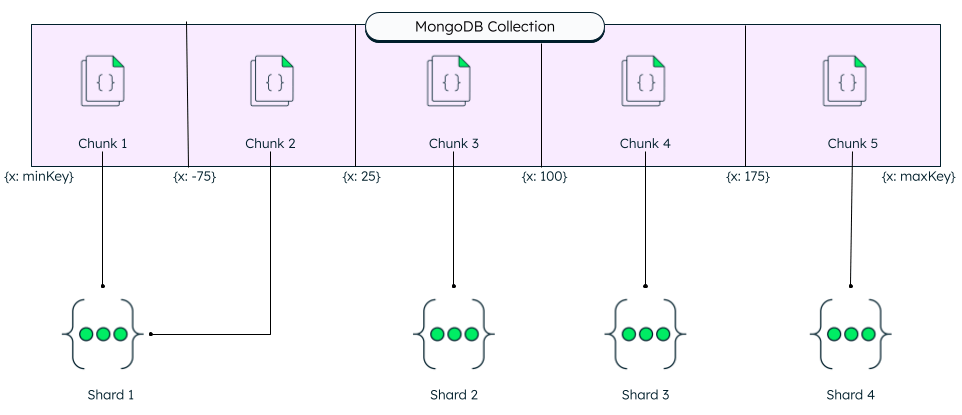
这里,x是决定文档分割范围的值——例如,x值在最小键值(例如-100)和-75之间形成数据块1,-75到25形成数据块2,依此类推。
分片键基于每个文档内的字段。那些字段中的值将根据分片范围和块数量决定文档所在的分片。这些数据存储并保存在配置服务器副本集中。
分片键值对直接影响集群性能,因此需要谨慎选择。错误选择的分片键可能导致性能或扩展性问题,因为数据块分布不均。您可以通过更改分片键来始终更改数据分布策略。使用文档来为您选择最佳的分片键。
均衡器
一个名为均衡器的后台进程自动在不同分片之间迁移数据块,以确保每个分片的数据量始终均匀。均衡器在副本集的主节点上运行。如果特定分片中的数据达到指定的阈值,均衡器将在分片之间迁移数据。均衡器还会解决向集群添加或从集群中删除分片时造成的失衡。
分片策略
分片策略是分布式数据库(如MongoDB)用于分区数据的方法。使用的策略类型可以取决于查询模式、应用程序用例和数据分布模式。例如,区域分片更适合需要根据客户地理位置划分数据的场景。
MongoDB支持以下分片策略来在分片集群中分配数据:
- 范围分片
- 哈希分片
- 区域分片
基于范围的分片
基于范围的分片根据分片键值将数据划分为范围。然后,根据分片键值将每个数据块分配到一个范围。
值“接近”的分片键范围更有可能位于同一数据块中。这允许进行定向操作,因为mongos可以将操作路由到仅包含所需数据的分片。
上一节中关于分片键的图示是范围分片的示例。
哈希分片
哈希分片涉及计算分片键字段值的哈希。然后,根据哈希分片键值将每个数据块分配到一个范围。

尽管分片键的范围可能“接近”,但它们的哈希值不太可能位于同一数据块中。基于哈希值的分布有助于更均匀的数据分布,尤其是在分片键单调变化的数据库集中。然而,哈希分片不提供基于范围的效率操作。
区域分片
区域分片根据应用程序要求将数据组织到不同的区域。例如,您可能希望将所有欧洲用户的数据存储在一起,因此可以创建一个包含所有欧洲客户数据的区域。每个区域可以关联一个或多个分片,每个分片可以包含一个或多个区域的数据。
如何在 MongoDB 中实现分片
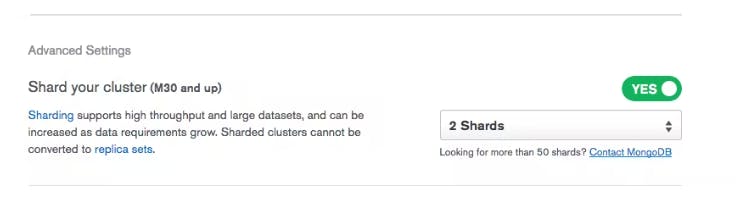
部署和管理分片集群最简单、最方便、最经济的方式是通过数据库即服务,它简化了分片集群的实现。
要启用分片,您需要从您的MongoDB Atlas集群开启它。
为什么使用MongoDB Atlas?
如果您想自行操作,请按照以下说明进行。确保用您的设置的相关值替换所有在 < 和 > 之间的内容。我们将设置一个配置服务器和分片(都在三个节点的副本集中),以及一个mongos服务器。
让我们开始吧。
1. 配置配置服务器
每个配置服务器副本集可以有任意数量的 mongod 进程(最多 50 个),但有以下例外:没有仲裁者和没有零优先级成员。对于每一个,您都需要使用 --configsvr 选项来启动它。例如
mongod --configsvr --replSet <configReplSetName> --dbpath <path> --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)>从那里,连接到 副本集成员中的一个
mongosh --host <hostname> --port 27019在 副本集成员中的一个 上运行 rs.initiate()
rs.initiate(
{
_id: "<configReplSetName>",
configsvr: true,
members: [
{ _id : 0, host : "<cfg1.example.net:27019>" },
{ _id : 1, host : "<cfg2.example.net:27019>" },
{ _id : 2, host : "<cfg3.example.net:27019>" }
]
}
)配置服务器副本集设置并运行后,我们可以创建分片。有关副本集配置的更多信息,请访问 MongoDB 官方文档页面 副本集配置。
2. 设置分片
如前所述,每个分片本身就是一个副本集。此过程将与配置服务器类似,但使用 --shardsvr 选项。请确保为每个分片使用不同的副本集名称。
mongod --shardsvr --replSet <shardReplicaSetNamereplSetname> --dbpath <path> --port 27018 --bind_ip <cluster hostname(s)|ip address(es)>从那里,连接到 副本集成员中的一个
mongosh --host <hostname> --port 27018并在 副本集成员中的一个 上运行 rs.initiate()。请确保省略 --configsvr 选项
rs.initiate(
{
_id: "<shardReplicaSetNamereplSetnamereplSetName>",
members: [
{ _id : 0, host : "<shard-host1.example.net:2701827019>" },
{ _id : 1, host : "<shard-host2.example.net:2701827019>" },
{ _id : 2, host : "<shard-host3.example.net:2701827019>" }
]
}
)3. 启动 mongos
最后,设置 mongos 并将其指向您的配置服务器副本集
mongos --configdb
<configReplSetName>/<cfg1.example.net:27019>,<cfg2.example.net:27019>,<cfg3.example.net:27019> --bind_ip localhost,<cluster hostname(s)|ip address(es)>在生产环境中,必须部署多个 mongos 以避免瓶颈。通常,至少启动三个 mongos 实例是一个好习惯。
4. 配置并开启数据库的分片
连接到您的 mongos
mongosh --host <hostname> --port <port>并将您的分片添加到集群中。为每个分片执行一次此操作
sh.addShard( "<shardReplicaSetName>/<shard-host1.example.net:27018>,<shard-host2.example.net:27018>,<shard-host3.example.net:27018>")在您的数据库上启用分片
sh.enableSharding("<database>")最后,使用 sh.shardCollection() 方法对集合进行分片。您可以通过 哈希分片 来执行此操作,这将在分片中均匀分布您的数据……
sh.shardCollection("<database>.<collection>", { <shard key field> : "hashed" , ... } )...或者通过 基于范围的分片,这允许您根据分片键值优化分片之间的分布。对于某些数据集,这将使跨数据范围查询更有效。命令如下
sh.shardCollection("<database>.<collection>", { <shard key field> : 1, ... } )到此为止!您现在已设置好了您的第一个分片集群。从现在起,任何应用程序交互都应通过路由器(mongos 实例)进行。