鉴于组织拥有的大数据资产不断增加,以及组织利益相关者对优化数据分析生产力和效率的需求快速增加,数据湖成为所有行业关键增长推动者的现象并不令人意外。而且,随着数据湖从以解决方案为基础的资源向基于服务和解决方案的资源转变,数据科学家、工程师以及其他STEM专业人士比以往任何时候都更容易获取数据湖。
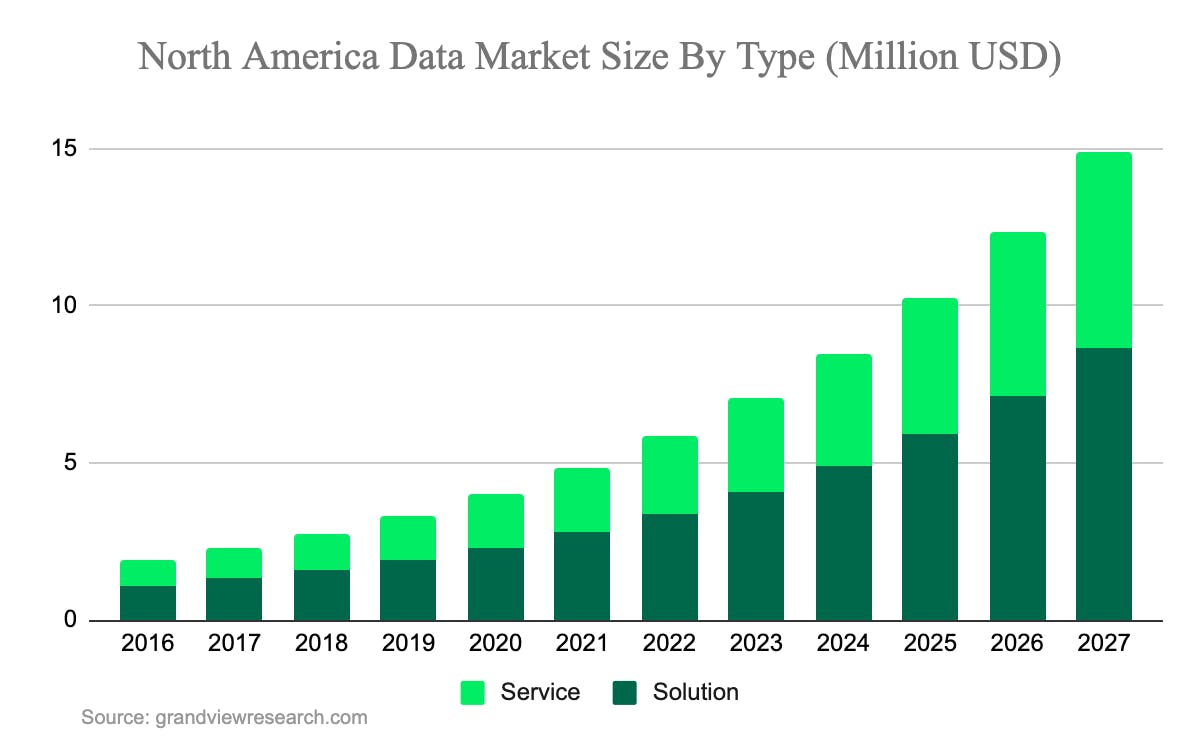
(来源:Grand View Research,2023)
数据湖能够摄取大量结构化数据、半结构化数据和未结构化数据的能力,以及它们在推动机器学习和高级数据科学中的日益增长的作用,都是预计从2020年到2027年数据湖市场将以20.6%的复合年增长率(CAGR)增长的一些原因。
综上所述,企业和STEM专业人士如何在自己的日常活动中利用数据湖,并充分利用云数据湖提供的众多好处呢?继续阅读以了解数据湖是什么,如何使用,数据湖与数据仓库的区别,以及如何为您的组织选择合适的数据湖解决方案或服务。
什么是数据湖?
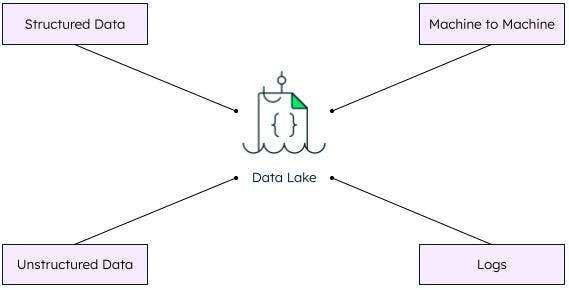
数据湖就是一个中央存储库,用于以原始(原始数据)格式存储大量数据。这意味着数据湖中的数据摄取不需要任何预格式化。这也意味着各种结构化数据、半结构化数据和无结构化数据类型(例如,关系型文件、文本文件、PDF文件、音频文件、JSON文档)也可以存储在同一个数据湖中。
数据湖特性
除了这种数据格式无关性之外,数据湖的一些其他特性还包括
- 多数据源:数据湖可以轻松地从各种数据源摄取多种数据类型。
批量加载:与逐个或顺序加载数据不同,许多数据湖能够批量加载大量数据,这不仅加快了摄取过程,也提高了性能。
先存储后分析:数据湖主要关注以原始格式存储数据,用于未来的数据发现和商业智能目的。这意味着在数据湖中,通常伴随数据仓库数据摄取的数据层次和标签分配不会最初发生。然而,为了避免创建数据沼泽(例如,用户无法看到数据湖中的数据类型),数据以扁平、非层次化的格式作为对象存储,并带有元数据,用户可以在以后访问。避免创建数据沼泽也是重要的,这样可以在数据湖中保持适当的数据安全性。
模式灵活性:数据湖存储系统能够从数据湖中先前摄取的数据中推断模式。这有时被称为“读模式”。这与数据仓库以预定义格式和层次结构摄取数据的方式有显著不同,有时称为“写模式”。
数据湖架构
与数据仓库架构及其相关平台预定义的性质相反,数据湖架构可以描述为一种架构模式,或者说是围绕大量原生格式数据存储库的一套工具(支持读取时模式的方法)。因此,数据湖架构往往因组织具体的数据使用和分析需求而异。
数据存储库
数据湖有三个基本元素与其数据存储库相关,包括
数据存储:在数据湖中,所有数据都以对象形式以扁平、非层次化的格式存储,并关联元数据。以这种方式存储数据是数据湖与数据仓库之间的重要区别。
数据湖文件格式:文件格式将数据压缩成列式格式(同时保留原始数据的原生状态),这使得在以后可以进行数据查询和分析。
数据湖表格式:数据湖表格式将所有数据源聚合到一个表中,因此当一个数据源被更新时,其他所有数据源也会更新。
一种常见的数据湖存储方法是用Hadoop分布式文件系统(HDFS)。Hadoop数据湖将数据存储在基于通用服务器硬件的集群计算节点上(EDUCBA,2023年)。虽然使用非HDFS生态系统组件的对象存储技术的数据存储正在变得越来越受欢迎,但需要注意的是,这些非HDFS数据湖解决方案通常是企业数据湖实施的一部分。
数据湖架构层
组织组装各种数据湖工具,以最佳地运行他们的读取时模式过程。有时,按照共同功能将这些工具分组,并按层次结构考虑这些组是有帮助的。数据湖架构中的基本五层包括
摄入层:在这个层次中,原始数据以实时或批处理方式摄入到数据湖中。然后,原始数据组织到一个逻辑文件夹结构中。需要注意的是,摄入层是数据湖流分析(例如,数据收集时,它实时分析,然后缩减为处理和存储的重要数据)发生的地方。这略不同于读取时模式,其中所有数据都摄入到数据湖中进行后续分析。
蒸馏层:从摄入层来的原始数据随后被转换成分析准备格式,包括列式文件和表格。数据编码、类型、推导和清洗也在此层发生。
- 处理层:这是找到分析算法和高级分析工具的层次。这里进行的一些活动包括数据异常检测、关联规则学习、数据聚类、数据分类、数据回归和数据集摘要。
洞察层:有时被称为研究层,这是探索和分析处理层模式和输出的地方。用于探索这些模式的最常见的数据库访问语言是SQL和NoSQL,但根据所需的研究和分析类型,可以使用许多其他编程语言,包括Python。数据科学家是这个层次发生的工作的一部分,对于有效的大数据分析是必不可少的。
操作层:操作层负责系统管理和监控。工作流管理、数据管理、数据治理和审计等活动都发生在这个层。
除了这些常见的层之外,通常还包括针对每个特定组织及其独特需求的网络安全、治理和合规性等附加元素。
数据湖与数据仓库的比较
数据湖与数据仓库之间的差异是显著的。然而,这些差异对最终用户来说并不容易辨别。相反,这些差异在数据集成、数据结构和数据存储方法上得到了突出,以及数据湖与数据仓库如何访问、查询和处理数据。

下表总结了数据湖与数据仓库之间的一些关键差异。
技术和数据演变对数据存储的影响
虽然数据仓库和数据湖都可以支持大数据的数据存储需求,但从容量方面来说,数据仓库解决方案在处理、存储和分析非结构化数据方面并不有效。这是因为数据仓库遵循关系数据库的规则,要求严格遵守预定义的数据格式和指导层次结构(例如,结构化数据,半结构化数据)。然而,生成的非结构化数据量远大于结构化数据。事实上,非结构化数据占所有当前企业数据的大约80%或更多。
此外,非数字、高度细粒度的数据常出现在科学研究、高级数学、医疗保健等领域。在这些领域,数据科学家和数据工程师正在积极使用人工智能(AI)和机器学习(ML)来执行数据挖掘、训练ML算法,并有效地在几分钟内而不是几天内分析大量非结构化数据。
机器学习和非结构化数据
依赖非结构化数据和机器学习数据湖的AI/ML活动示例包括
图像分析:机器学习被积极用于审查大量图像,以快速识别MRI/X光片中可能的病人问题,实时识别生产线上的制造缺陷,或用于将大量气象图像进行分割,以供气候变化研究。
音频分析:机器学习常用于分析声音文件,以便主动检测制造设备可能的维护问题,完成安全和法律执法目的的语音识别和分析,以及分割音频文件(例如,音乐类型、艺术家)。
视频分析:使用机器学习分析商业客运和供应链运输中的驾驶员行为和安全已成为日常现象。此外,机器学习甚至被用于帮助运动员在比赛期间通过跟踪身体位置和物体轨迹来提高他们的表现。此外,通过机器学习快速识别和分割视频文件现在成为可能。
文本分析:自然语言处理(NLP)是一种人工智能形式,用于分析文本文件,从识别数据源到提炼内容情感(例如,不满的客户与满意的客户),或从数字化文档中提取所需内容。此外,文本分析是任何组织社交媒体策略的关键部分。
这就是为什么云数据湖已成为大数据存储及其相关大数据分析的关键原因之一。
如何选择合适的数据湖工具
在考虑潜在云数据湖选项时,进行广泛的研究当然很重要。然而,在开始研究之前,花点时间考虑以下组织的使用案例/需求。
关键数据湖解决方案问题
主要用例:您预计您的组织将如何最频繁地使用云数据湖?是作为更低成本的数据存储选项以供商业软件使用,长期取代企业数据仓库,还是您的数据流和数据湖将作为现有企业数据仓库的补充,用于存储数据科学家可以访问的非结构化数据,同时去除业务分析师受益的数据孤岛?
与数据仓库共存:许多组织在保留现有数据仓库的同时进入云数据湖的世界。如果这是可能的,考虑数据仓库技术将如何与数据湖协同工作,日常运营相关的数据将如何存储在多个仓库和数据湖中,以及如何管理精选数据。理想情况下,如果同时使用数据仓库和数据湖,数据分析工作流程和访问将是组织数据分析战略的良好规划元素。
可扩展性和灵活性:好消息是,数据湖比数据仓库更容易扩展,但仍重要的是要了解近期和中期内可能发生的数据需求变化。您预计在启动时,18到24个月内以及之后将摄入哪些数据资产到您的数据湖解决方案中?
用户类型:虽然数据湖在摄入和存储社交媒体数据(例如,文本文件、视频、图像)方面确实非常出色,但重要的是要记住,独立使用时,它们没有OLAP活动管理或CMR工具的能力。随着您的组织建立需求,记住业务营销专业人士可能需要额外的软件来访问您的数据湖洞察力,而数据科学家则可能能够直接访问非结构化数据。
数据管理和治理策略:数据仓库和数据湖在数据管理和治理的最佳实践中存在差异。在数据仓库中,挑战在于在摄取之前对数据进行格式化、标记和清洗;而在数据湖中,挑战在于一旦摄取后维持数据质量,以避免创建数据沼泽。对于刚开始使用云数据湖的组织,这需要转变数据管理和治理策略。您的数据管理和数据治理策略在实施数据湖解决方案时将如何转变?
内部技能集:如果您的组织没有数据湖,评估与这种存储类型相关的内部实力是重要的。数据库管理员和数据湖工程师通常不拥有相同的技能集。此外,管理数据湖的大数据工程师需求很高,且难以找到。对于一些人来说,在内部技能集完全开发之前,与数据湖服务提供商或承包商合作是有意义的。
额外研究
一旦您的组织需求和用例进一步细化,是时候进行一些供应商和工具研究。需要考虑的事项包括
供应商/工具的可靠性和性能评分。
供应商/工具的网络安全态势。
工具与其他平台或选定的工具集成的简便性。
产品与所需功能和功能的兼容性。
产品与供应商与所需合规标准的兼容性。
此外,参考评级报告(如Gartner、Forrester和G2)可能有助于更好地了解数据湖市场中供应商和工具的排名以及您自己的行业。
查看您所在行业的专家博客,以及审查您所在行业垂直领域的有影响力的云管理组织举办的网络研讨会,可以帮助了解其他已实施所考虑平台和工具的人的经验。这也可以更新您对特定学科相关技术当前趋势的了解。
顶级数据湖工具
数据湖解决方案的一个好处是,它们可以根据组织的需求进行高度定制。以下是一些提供灵活和可扩展存储以构建数据湖的技术示例
构建数据湖的技术
AWS数据湖构建/Amazon Simple Storage Service (AWS S3)
Azure数据湖存储Gen2
Google Cloud Storage
Snowflake
用于在数据湖中组织和查询数据的工具
AWS Athena
Databricks SQL Analytics
MongoDB Atlas Data Federation
Presto
Starburst
与数据湖协同工作的大数据分析工具
Alteryx
Azure Databricks
Databricks Lakehouse平台
Google Cloud
MATLAB
Qubole
Starburst
常见问题解答
什么是数据湖?
数据湖是一个集中式仓库,用于以原始(原始数据)格式存储大量数据。这意味着数据湖的数据摄取不需要任何类型的预格式化。
数据湖的关键特征是什么?
数据湖的一些关键特征包括
多租户(一个软件实例为多个客户服务)。
读取时模式的数据摄取。
以原生状态存储非结构化数据。
“先存储,后分析”的焦点。
数据湖架构的主要层次是什么?
数据湖的主要架构层包括
摄取层:在这个层中,原始数据以实时或批量方式被摄取到数据湖中。
精炼层:摄取层中的原始数据随后被转换成适合分析的格式,包括列式文件和表格。
处理层:这是包含分析算法和高级分析工具的层。
洞察层:有时也称为研究层,这是探索和分析处理层中的模式和输出的地方。
操作层:操作层负责系统管理和监控。
数据湖和数据仓库之间有哪些主要区别?
数据湖和数据仓库之间有很多区别。其中两个主要区别包括
模式灵活性:在数据湖中,使用称为“读取时模式”的方法来确定数据模式的结构。这意味着实际摄取的数据以及数据湖中现有的数据决定了任何给定时间使用的模式。而在数据仓库中,使用称为“写入时模式”的方法——这意味着所有被摄取的数据都必须使用预定义的模式、层次结构等。
存储的数据类型:数据湖能够以各自原生状态存储所有类型的结构化数据、半结构化数据和未结构化数据。然而,数据仓库只能在将数据处理成预定义的格式和层次结构后存储结构化和半结构化数据。