R是一种强大的流行语言,用于统计分析、建模和可视化。MongoDB提供强大的查询功能,用于快速检索和分析大数据,其灵活的模式使其成为非结构化数据集的自然选择。通过连接MongoDB和R,我们可以使用MongoDB聚合管道(MongoDB aggregation pipeline)快速进行高级数据分析。
继续阅读,了解有关R MongoDB驱动程序的更多信息,并开始使用它们进行数据分析。
在R中使用MongoDB入门
要安装R,请从CRAN下载页面下载您操作系统的相关软件包。
然后,您可以使用RStudio的最新版本安装和查看结果和可视化,所有这些都在一个地方。
您还需要运行MongoDB。我们建议您尝试本教程的MongoDB Atlas免费层集群。MongoDB Atlas易于设置,并提供R MongoDB示例的样本数据集。您可以在集群页面上集合按钮旁边的“…”处使用样本数据集。
MongoDB的R包
您需要一个MongoDB客户端,在R中建立可靠的MongoDB连接。首选的R MongoDB驱动程序mongolite快速,语法类似于MongoDB shell。mongolite将是以下示例中使用的驱动程序。以下列出的其他软件包在GitHub上最近没有这么活跃。连接MongoDB和R的最受欢迎的软件包包括
- mongolite:一种较新的R MongoDB驱动程序,mongolite可以执行各种操作,如索引、聚合管道、TLS加密和SASL身份验证等。它是基于R的jsonlite软件包和mongo-c-driver。我们可以从CRAN或从RStudio(在后续部分中解释)安装mongolite。
RMongo:RMongo是第一个具有简单R MongoDB界面的R MongoDB驱动程序。它具有类似于MongoDB shell的语法。截至现在,RMongo已被弃用。
rmongodb:rmongodb具有创建管道、处理BSON对象等功能。与mongolite相比,其语法非常复杂。rmongodb与RMongo一样已被弃用,目前在CRAN上不可用或不再维护。
如何在R中连接到MongoDB数据库
MongoDB Atlas免费集群中提供了几个示例数据集。您将使用sample_training数据库,因为它包含许多适合使用R进行数据分析的集合。
打开RStudio(或您选择的任何IDE/编辑器)。创建一个名为trips_collection.R的新文档。您可以为这个教程中使用的每个集合创建一个单独的文件(请参阅github仓库)。
在新建的文件(或使用RStudio时的控制台)中运行以下命令来安装mongolite:
install.packages("mongolite")然后,使用以下命令加载它:
library(mongolite)接下来,使用R代码中的mongo()函数连接到MongoDB并检索集合,从sample_training数据库中获取trips集合。此集合包含纽约市一家自行车共享服务用户的行程数据。此集合。
# This is the connection_string. You can get the exact url from your MongoDB cluster screen
connection_string = 'mongodb+srv://<username>:<password>@<cluster-name>.mongodb.net/sample_training'
trips_collection = mongo(collection="trips", db="sample_training", url=connection_string)您可以通过检查此数据库中文档的总数来验证您的代码现在是否已连接到MongoDB集合。要做到这一点,请使用count()方法。
> trips_collection$count()
[1] 10000现在您已建立到数据库的连接,您将能够从中读取数据并由R进行处理。
如何将数据从MongoDB导入R
在本节中,您将学习如何从MongoDB检索数据并将其显示出来。让我们继续上一节中的trips_collection。
您可以使用MongoDB Atlas UI查看trip_collection文档,或使用RStudio进行可视化。
使用$iterate()$one()方法获取集合的任意一个样本文档,以检查此集合的数据结构。
> trips_collection$iterate()$one()
$tripduration
[1] 379
...现在您知道了文档的结构,您可以执行更复杂的查询,例如从trips集合数据中找到五个最长骑行并按时间顺序列出。
> trips_collection$find(sort = '{"tripduration" : -1}' , limit = 5, fields = '{"_id" : true, "tripduration" : true}')
_id tripduration
1 572bb8222b288919b68ac07c 326222
2 572bb8232b288919b68b0f0d 279620
3 572bb8232b288919b68b0593 173357
4 572bb8232b288919b68ae9ee 152023
5 572bb8222b288919b68ac1f0 146099上述查询使用了排序和限制运算符来生成此结果集。
如何在R中分析MongoDB数据
为了更详细地使用R分析MongoDB,您可以使用MongoDB聚合框架。此框架允许操作符创建聚合管道,以帮助通过单个查询获取确切的数据。
假设您想检查有多少订阅者在骑行时间大于500秒后返回到他们出发的同一站。此查询使用MongoDB $expr (expressions)在同一个文档中比较两个字段。
query = trips_collection$find('{"usertype":"Subscriber","tripduration":{"$gt":500},"$expr": {"$eq": ["$start station name","$end station name"]}}')
# Get number of records using nrow method
nrow(query)
[1] 97结合这些运算符和一些R代码,您还可以查看哪种类型的用户更常见:订阅者还是一次性客户。为此,请按usertype字段分组用户。
user_types = trips_collection$aggregate('[{"$group":{"_id":"$usertype", "Count": {"$sum":1}}}]')要比较结果,您可以可视化数据。将mongolite获取的数据转换为dataframe并使用ggplot2进行绘图会更方便。
df <- as.data.frame(user_types)
install.packages("tidyverse", dependencies=T)
install.packages("lubridate")
install.packages("ggplot2")
library(tidyverse)
library(lubridate)
library(ggplot2)
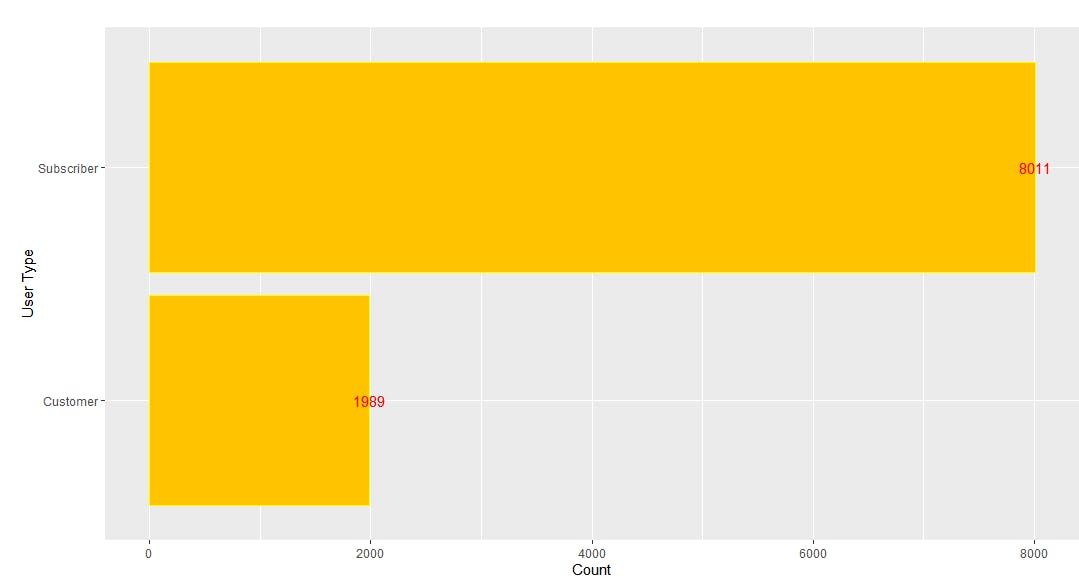
ggplot(df,aes(x=reorder(`_id`,Count),y=Count))+
geom_bar(stat="identity",color='yellow',fill='#FFC300')+geom_text(aes(label = Count), color = "red") +coord_flip()+xlab("User Type")您应该在RStudio中看到以下图形
让我们探索另一个条形图,使用不同的数据集——《code>inspections。 这个数据集 包含关于纽约市建筑检查及其是否通过的数据。以下示例中,从名为 inspections_collection.R 的新文件开始。
inspections_collection = mongo(collection="inspections", db="sample_training", url=connection_string)假设你想检查2015年和2016年未通过检查的公司数量。
如果你在 Atlas UI 中查看数据,你会注意到日期字段是字符串类型。要将其转换为日期类型并提取年份,需要一些处理——或者你可能这样认为。但,使用 MongoDB 聚合管道,你可以在单个查询中完成所有操作。对于操作日期字段,使用 $addFields 操作符。
year_failures = inspections_collection$aggregate('[{"$addFields": {"format_year":{"$year":{"$toDate":"$date"}}}},
{"$match":{"result":"Fail"}},
{"$group":{"_id":"$format_year", "Failed": {"$sum":1}}}]')你正在按年份分组结果,因此创建图表很容易
df<-as.data.frame(year_failures)
ggplot(df,aes(x=reorder(`_id`,Failed),y=Failed))+
geom_bar(stat="identity", width=0.4, color='skyblue',fill='skyblue')+
geom_text(aes(label = Failed), color = "black") +coord_flip()+xlab("Year")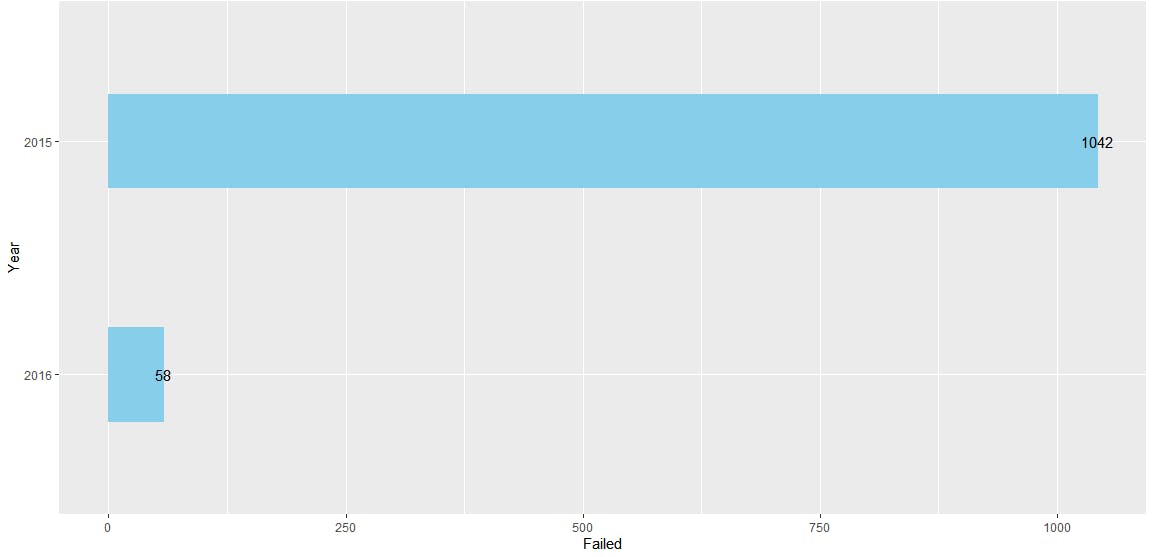
你可以在 RStudio 中看到这个新的图表。使用聚合框架使得从数据库中提取数据并将其结构化以方便 R 在图表中绘图变得容易。
接下来,让我们创建一个折线图。让我们使用 companies 数据集,它包含有关公司(如成立年份和总部地址)的信息。要探索这个数据集,创建一个新文件 companies_collections.R。
比如说你想知道2003年之后成立的 category_code = 'consulting' 类型的公司数量趋势。为此,使用关系操作符 $gt,按 founded_year 分组结果,并排序以在折线图中显示。同样,这也可以在一个查询中完成。
companies_collection = mongo(collection="companies", db="sample_training", url=connection_string)
consulting_companies_year_wise = companies_collection$aggregate('[
{"$match":{"category_code":"consulting","founded_year":{"$gt":2003}}},
{"$group":{"_id":"$founded_year", "Count": {"$sum":1}}},
{"$sort":{"_id": 1}}
]')
df<-as.data.frame(consulting_companies_year_wise)
ggplot(df,aes(x=`_id`,y=Count))+
geom_line(size=2,color="blue")+
geom_point(size=4,color="red")+
ylab("Number of consulting companies")+ggtitle("Year-wise (2004 onwards) companies founded in the category 'consulting'")+xlab("Year")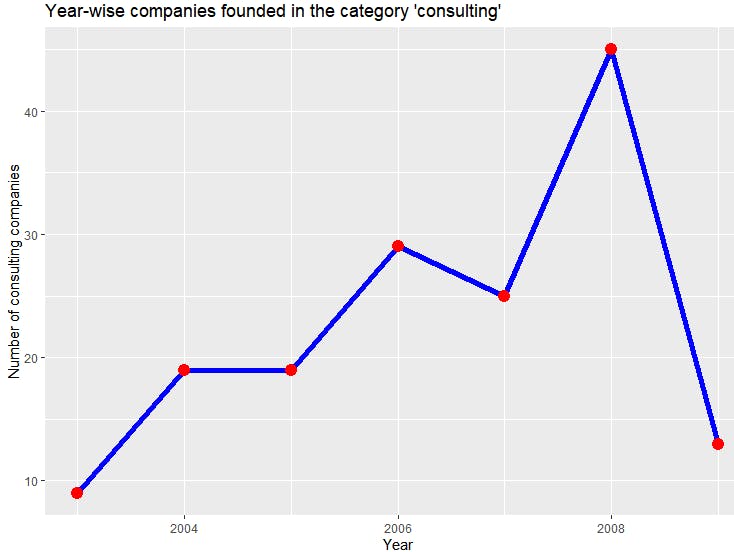
你可以看到咨询公司的数量在2008年之前稳步增加,之后急剧下降。再次证明,使用聚合框架使得数据转换成与 R 一起使用时易于使用的格式变得容易。
你还可以从 MongoDB 收到的数据中创建地图。让我们找到名为 Facebook 的公司的所有办公地点。注意,offices 字段是一个包含许多具有 city、latitude 和 longitude 等字段的对象的数组。要检索单个对象和字段,使用 $unwind 聚合操作符——另一个可以将最复杂的对象简化以高效提取数据的操作符。
# Get the location array objects
fb_locs = companies_collection$aggregate('[{"$match":{"name":"Facebook"}},{"$unwind":{"path":"$offices"}}]')
# Get individual fields from each array object
loc_long <- fb_locs$offices$longitude
loc_lat <- fb_locs$offices$latitude
loc_city <- fb_locs$offices$city
# Plot the map
install.packages("maps")
library(maps)
map("world", fill=TRUE, col="white", bg="lightblue", ylim=c(-60, 90), mar=c(0,0,0,0))
points(loc_long,loc_lat, col="red", pch=16)
text(loc_long, y = loc_lat, loc_city, pos = 4, col="red")对于更高级的分析,你还可以使用像 ggmap 这样的复杂 API。由于这是一个简单的显示,使用基本的 map() 函数。
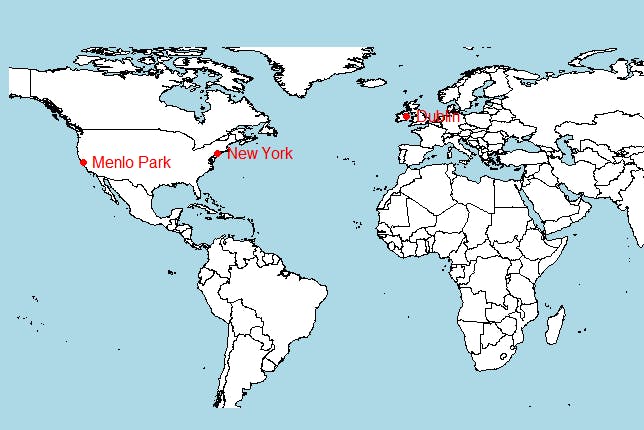
MongoDB 和 R 允许你执行不同类型的分析。R 也因从数据中提取统计信息而受到欢迎。为了理解这一点,让我们使用 grades 数据集,它包含关于一组作业的学生成绩信息。创建一个新文件 grades_collection.R,在其中将加载此数据集。
grades_collection = mongo(collection="grades", db="sample_training", url=connection_string)让我们获取所有学生中参加了编号为 7 的课程的学生的所有分数的平均值。使用 $project 获取仅特定字段。
class_score_allstudents = grades_collection$aggregate('[{"$match":{"class_id":7}},{"$unwind":{"path": "$scores"}},{"$project":{"scores.score":1,"_id":0,"scores.type":1,"class_id":1}}]')分数字段是一个对象,其中包含 type 和 score 字段。你可以将所有分数值提取到单个向量中
score_values <- class_score_allstudents$scores$scoreR为我们提供了许多工具来处理这些成绩中的数据。使用统计函数获取班级的中位数和平均值。
> median(score_values)
[1] 49.96923
> mean(score_values)
[1] 50.80008您可以使用箱线图获取相同信息以及更多信息。
b<-boxplot(score_values,col="orange",main = "Overall score details of all students attending class with id '7'")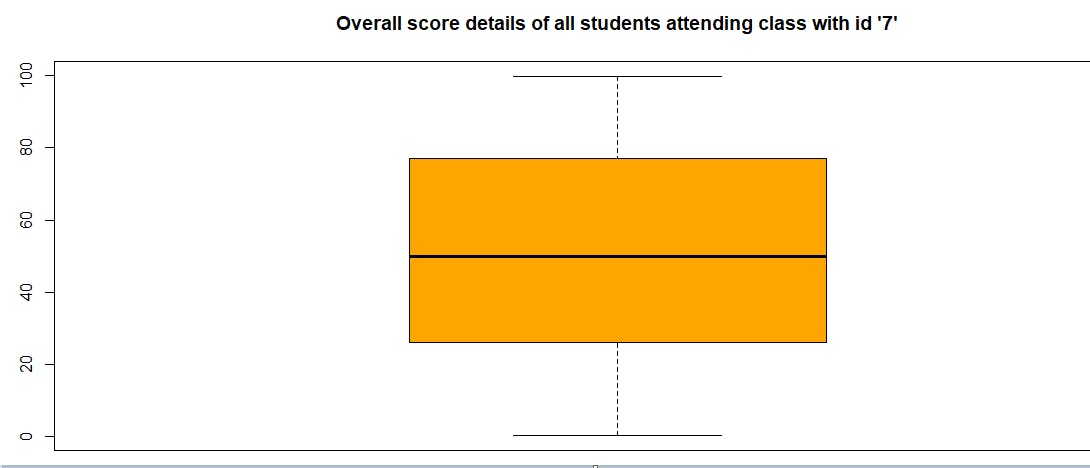
您可以使用stripchart函数(点击查看)来添加所有数据点。
stripchart(score_values, method = "jitter", pch = 19, add = TRUE, col = "black", vertical=TRUE)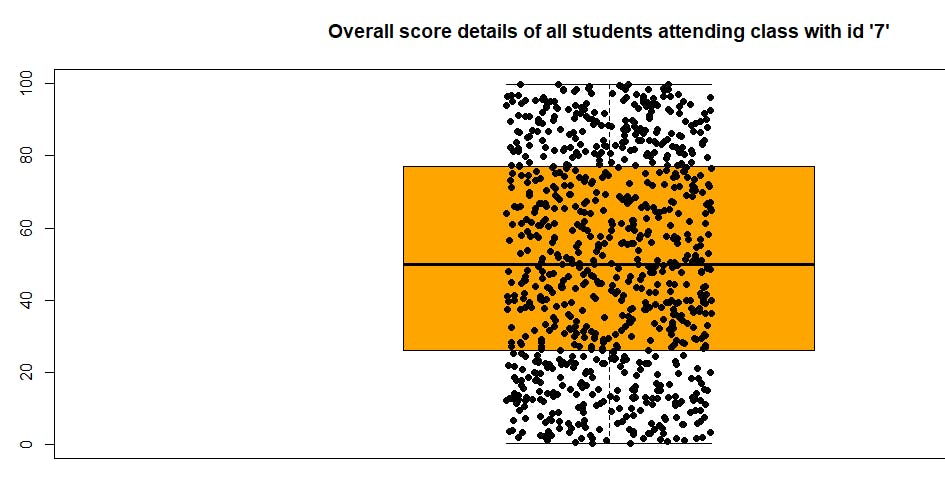
使用$stats函数在控制台上查看相同的统计信息。
> b$stats
[,1]
[1,] 0.1798022
[2,] 25.9990090
[3,] 49.9692287
[4,] 77.0596579
[5,] 99.9447486
>您还可以绘制直方图来查看考试中class_id 7学生分数的分布范围。
# Get the scores array
student_score_exam = grades_collection$aggregate('[{"$unwind":{"path": "$scores"}},{"$match":{"class_id":7,"scores.type":"exam"}}]')
# Get the score values for 'exam' field for all the students
scores_of_allstudents <- student_score_exam$scores$score
hist(scores_of_allstudents,col="skyblue",border="black",xlab="Scores of all students of class id 7")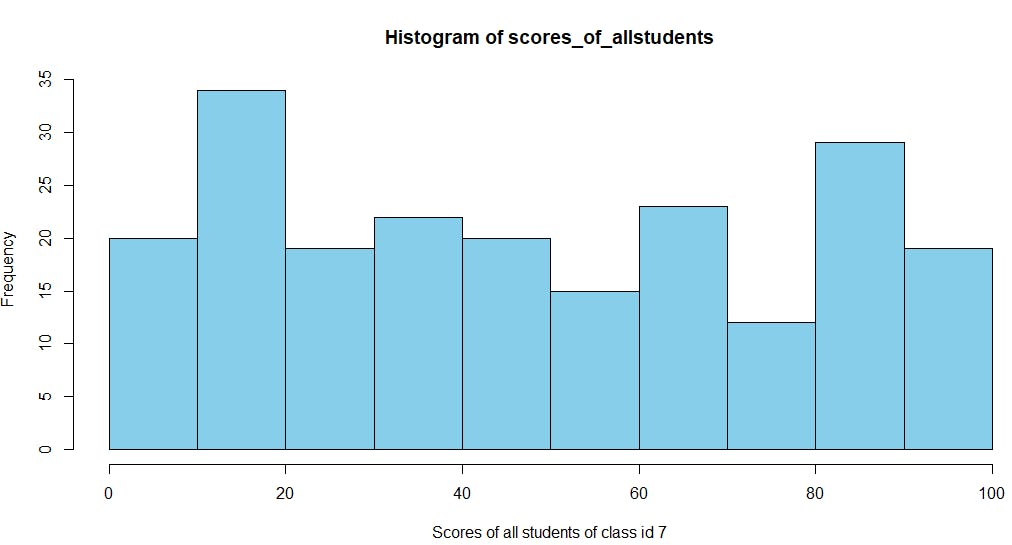
要查看范围(最小和最大值)以及所有数据点,请分别使用R函数range()和sort()。
sort(scores_of_allstudents)
range_scores = range(scores_of_allstudents)
[1] 0.2427541 98.6759967您可以使用MongoDB和R执行许多复杂的操作和数据分析。现在,您已经有了数据集和实际操作经验,可以尝试更多。
结论
通过本MongoDB和R教程,您学习了如何连接MongoDB和R,并探索了各种集合以执行数据分析。您看到了如何执行复杂的操作和数据分析。作为下一步,您可以探索使用异构数据源进行数据分析。
常见问题解答
我可以从MongoDB导入数据到R吗?
是的,您可以使用mongolite、RMongo和rmongodb等几个包从MongoDB导入数据到R。Mongolite是一个快速且简单的R MongoDB驱动程序,支持所有基本操作。Mongolite会自动将MongoDB结果简化为R数据结构。
Mongolite还支持高级操作,如索引、查询、map-reduce、聚合管道等。其他两个驱动程序已弃用。