当需要处理和/或分析传统关系型数据库无法处理的数据集时,解决方案是将技术组织成一个称为大数据架构的结构。用例包括:
大数据架构组件
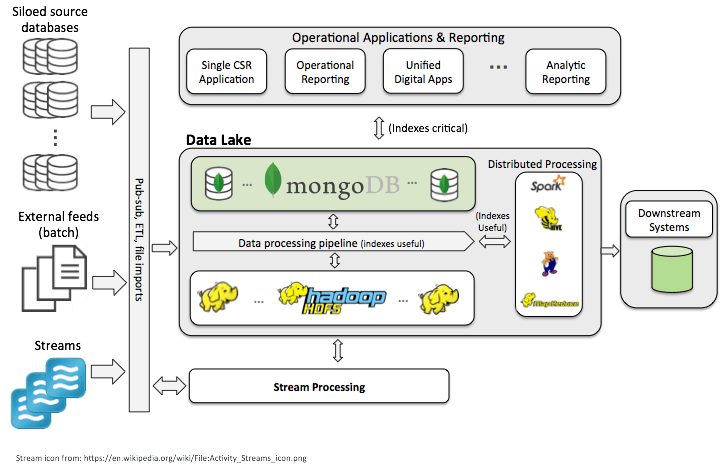
大数据架构具有多个层级或组件。以下是最常见的:
1. 数据源
数据来自多种格式的多种输入,包括结构化和非结构化。来源包括与 ERP 或 CRM 等应用程序关联的关系型数据库,数据仓库,移动设备,社交媒体,电子邮件和实时流数据输入,如物联网设备。数据可以批量或实时摄入。
2. 数据存储
这是数据接收层,它摄入数据,存储它并将非结构化数据转换为分析工具可以处理的形式。结构化数据通常存储在关系型数据库中,而非结构化数据可以存储在 NoSQL 数据库中,如 MongoDB Atlas。Hadoop 分布式文件系统 (HDFS) 等专用分布式系统是处理各种格式的大量批处理数据的良好选择。
3. 批处理
在处理非常庞大的数据集时,需要运行长时间批处理作业以筛选、合并和通常使数据可用于分析。源文件通常被读取和处理,输出写入新文件。Hadoop是这种情况下常用的解决方案。
4. 实时消息摄取
此组件专注于对数据进行分类,以便顺利过渡到环境的深层。为实时源设计的架构需要一个机制来摄取和存储实时消息以进行流处理。消息有时可以直接放入文件夹,但在其他情况下,需要一个消息捕获存储以进行缓冲,并支持扩展处理、可靠交付和其他排队需求。
5. 流处理
一旦捕获,实时消息必须经过筛选、聚合等处理,然后写入输出汇。此阶段的选项包括Azure Stream Analytics、Apache Storm和Apache Spark Streaming。
6. 分析数据存储
处理后的数据现在可以以结构化格式呈现,例如关系型数据仓库,以便由分析工具查询,就像传统的商业智能(BI)平台一样。其他用于提供数据的选择方案包括低延迟的NoSQL技术或交互式Hive数据库。
7. 分析和报告
大多数大数据平台都侧重于通过分析和报告从存储的数据中提取业务洞察。这需要多个工具。结构化数据相对容易处理,而对于非结构化数据则需要更高级和专业的技术。数据科学家可以使用各种笔记本和工具集进行交互式数据探索。架构中也可能包含数据建模层,这可能还支持使用流行的可视化和建模技术进行自助BI。
分析结果被发送到报告组件,该组件将它们复制到各种输出系统,供人类查看、业务流程和应用程序使用。在可视化为报告或仪表板后,分析结果被用于数据驱动的业务决策。
8. 编排
大数据分析节奏涉及多个数据处理操作,然后是数据转换、源和汇之间的移动以及将准备好的数据加载到分析数据存储中。这些工作流程可以使用Apache的Oozie和Sqoop或Azure Data Factory等编排系统进行自动化。
大数据架构的好处
1. 高性能并行计算
为了快速处理大数据集,大数据架构使用并行计算,其中多处理器服务器同时执行众多计算。大型问题被分解为更小的单元,可以同时解决。
2. 弹性可伸缩性
大数据架构可以横向扩展,使环境能够根据每个工作负载的大小进行调整。大数据解决方案通常在云中运行,您只需为实际使用的存储和计算资源付费。
3. 选择自由
市场提供了许多用于大数据架构的解决方案和平台,例如Azure托管服务、MongoDB Atlas和Apache技术。您可以将解决方案组合起来,以适应您的各种工作负载、现有系统和IT技能集。
4. 与相关系统的互操作性
您可以根据不同类型的工作负载创建集成平台,利用大数据架构组件进行物联网处理、BI以及分析工作流程。
大数据架构挑战
1. 安全性
静态类型的大数据通常存储在集中的数据湖中。需要强大的安全措施来确保您的数据免受入侵和盗窃。但是,由于其他应用程序也需要消耗数据,因此设置安全访问可能很困难。
2. 复杂性
大数据架构通常包含许多相互关联的组件。这包括多个数据源和各自的数据摄取组件,以及许多跨组件的配置设置以优化性能。构建、测试和故障排除大数据流程是具有高度知识和技能的挑战。
3. 技术演变
选择正确的解决方案和组件来满足大数据项目的商业目标是至关重要的。这可能是一项艰巨的任务,因为许多大数据技术、实践和标准相对较新,并且仍在发展过程中。Hive和Pig等核心Hadoop组件已经达到了一定的稳定性,但其他技术和服务仍然不成熟,并且可能随着时间的推移而发生变化。
4. 专业技能
基于主流语言的Big Data API正在逐渐得到应用。然而,大数据架构和解决方案通常使用非常规的、高度专业化的语言和框架,这对开发人员和数据分析师来说都有相当的学习曲线。