
解决方案概述
在此解决方案中,您将了解如何轻松使用MongoDB和Databricks构建基于ML的欺诈解决方案。该解决方案的关键特性包括通过集成外部数据源实现数据完整性、实时处理以确保及时检测欺诈、使用AI/ML建模来识别潜在的欺诈模式、实时监控以进行即时分析、模型可观察性以全面了解欺诈行为、灵活性、可扩展性和强大的安全措施。该系统旨在简化操作并促进应用程序开发与数据科学团队之间的协作。此外,它支持端到端CI/CD管道以确保系统和安全。
现有挑战
- 来自旧系统的数据可见性不完整:缺乏访问相关数据源阻碍了欺诈模式检测。
- 欺诈预防系统中的延迟问题:旧系统缺乏实时处理,导致欺诈检测延迟。
- 适应旧系统困难:缺乏灵活性阻碍了先进欺诈预防技术的采用。
- 老旧系统中的弱安全协议:过时的安全措施暴露了网络攻击的漏洞。
- 技术蔓延带来的运营挑战:多样的技术使维护和更新变得复杂。
- 老旧系统的运营成本高:昂贵的维护费用限制了欺诈预防预算。
- 团队间的协作不足:孤立的方法导致解决方案延迟和成本增加。

参考架构
基于机器学习的欺诈解决方案适用于那些实时处理、AI/ML建模、模型可观察性、灵活性和团队间协作至关重要的行业。系统通过端到端CI/CD管道确保操作始终更新和安全。相关行业包括
- 金融服务 - 交易中的欺诈检测
- 电子商务 - 订单中的欺诈检测
- 医疗保健和保险 - 索赔中的欺诈检测
数据模型方法

从领域图中可以看出,在处理信用卡交易时存在三个实体:交易本身、参与交易的商家和付款人。由于这三个实体都很重要,并在我们的欺诈检测应用程序中一起访问,因此我们使用扩展的参考模式,并在单个文档中包括关于交易、商家和付款人的字段。
构建解决方案
上述功能特性可以通过几个架构组件实现。这些包括
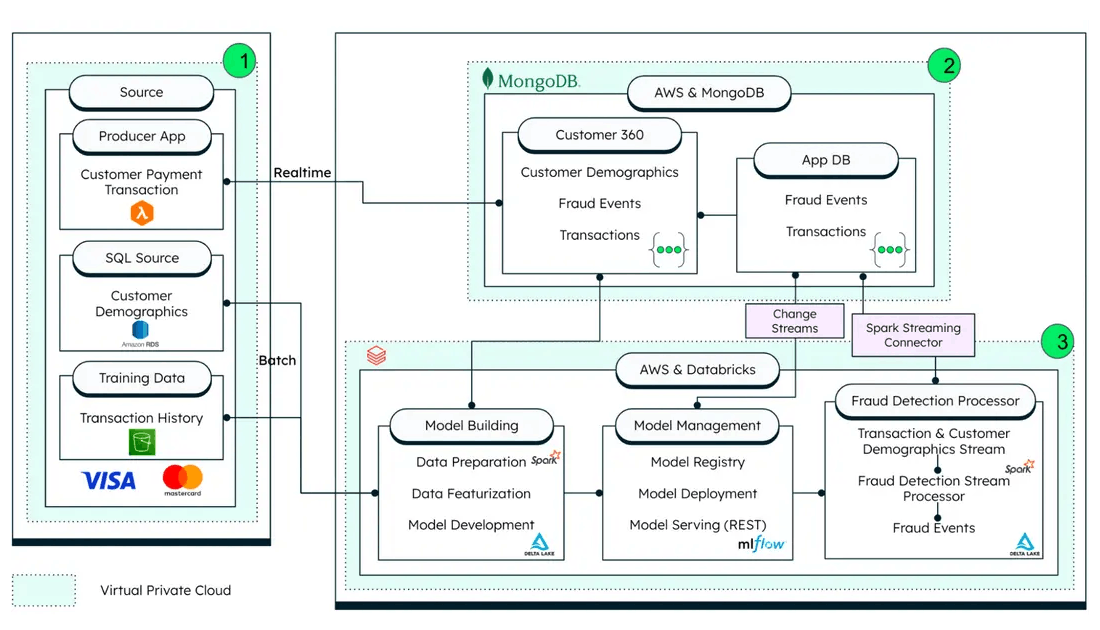
- 数据来源
- 生产者应用:生产者移动应用模拟实时交易的产生。
- 老旧数据源:SQL外部数据源用于客户人口统计信息。
- 训练数据:用于模型训练的历史交易数据来源于云对象存储 - 亚马逊S3或微软Azure Blob存储。
- MongoDB Atlas:作为卡交易的运营数据存储(ODS),并实时处理交易。该解决方案利用MongoDB Atlas的聚合框架进行应用内分析,并根据预配置的规则处理交易。它还通过本机Spark连接器与Databricks通信,以进行基于AI/ML的高级欺诈检测。MongoDB Atlas
- Databricks:托管AI/ML平台,以补充MongoDB Atlas的应用内分析。本例中使用的欺诈检测算法是一个由Databricks的欺诈框架MLFlow启发的笔记本,它已用于管理该模型的MLOps。训练后的模型作为REST端点公开。
现在,让我们更详细地逐一分析以下这些架构组件。
数据来源
实施全面的欺诈检测解决方案的第一步是从所有相关数据源聚合数据。如图1所示,采用事件驱动的联邦架构来收集和处理来自实时源(如生产者应用程序)、批处理遗留系统数据源(如SQL数据库)以及离线存储的历史训练数据集的数据。这种方法可以从交易摘要、客户人口统计、商户信息和其他相关来源等多个方面获取数据,确保数据完整性。
此外,所提出的事件驱动架构提供以下好处
- 实时交易数据统一,允许实时收集卡交易事件数据,例如交易金额、位置、交易时间、支付网关信息和支付设备信息。
- 帮助根据实时事件活动重新训练监控模型,以应对发生的欺诈行为。
演示中的生产应用程序是一个Python脚本,以预定义的速率(交易/秒,可配置)生成实时交易信息。
MongoDB事件驱动、左移分析架构
MongoDB Atlas是一个托管开发数据平台,提供了一些功能,使其成为卡欺诈交易分类的数据存储器的理想选择。它支持灵活的数据模型,可以处理各种类型的数据,具有高可扩展性以满足需求,提供高级安全功能以支持符合监管要求,实时数据处理以快速准确地进行欺诈检测,以及基于云的部署,以便将数据存储得更接近客户,并符合当地数据隐私法规。
MongoDB Spark Streaming Connector将Apache Spark和MongoDB集成。由Databricks托管的Apache Spark允许实时处理大量数据。Spark Connector将MongoDB数据转换为Spark数据帧,并支持实时Spark流。
MongoDB提供的App Services功能允许通过更改流和触发器实时处理数据。由于MongoDB Atlas能够存储和处理各种类型的数据,以及流能力和触发功能,因此它非常适合用于事件驱动架构。
此解决方案使用MongoDB和App Services丰富的连接器生态系统实时处理交易。通过调用Databricks MLflow框架托管的人工智能/机器学习模型的REST服务调用,使用App Service触发功能。
示例解决方案通过在用户设置集合中存储用户定义的支付限额和信息来管理基于规则的欺诈预防,如图所示。这包括每笔交易的最大美元限额、每天允许的交易次数以及其他与用户相关的详细信息。通过在调用昂贵的AI/ML模型之前根据这些规则过滤交易,降低了欺诈预防的整体成本。
Databricks作为AI/ML ops平台
Databricks是一个强大的AI/ML平台,用于开发识别欺诈交易的模型。Databricks的一个关键特性是支持实时分析。如上所述,实时分析是现代欺诈检测系统的一个关键特性。
数据工坊集成了MLFlow,这是一个强大的机器学习生命周期管理工具。MLFlow允许用户跟踪实验、重现结果和大规模部署模型,使管理复杂的机器学习工作流程变得更加容易。MLFlow提供模型可观察性,可以轻松跟踪模型性能和调试。这包括对模型指标、日志和其他相关数据的访问,可以用来识别问题并随着时间的推移提高模型的准确性。此外,这些功能还有助于设计使用人工智能/机器学习的现代欺诈检测系统。
使用的技术和产品
MongoDB Atlas开发者数据平台
合作伙伴技术
关键考虑因素
所提出解决方案的功能性和非功能性特性包括
- 数据完整性:与外部源集成,以进行准确的数据分析
- 实时处理:能够及时检测欺诈活动
- AI/ML建模:识别潜在的欺诈模式和行为
- 实时监控:允许即时数据处理和分析
- 模型可观察性:确保对欺诈模式有全面可见性
- 灵活性和可扩展性:适应不断变化的业务需求
- 强大的安全措施:防止潜在的违规行为
- 易于操作:减少操作复杂性
- 应用和数据科学团队合作:协调目标和合作
- 端到端CI/CD管道支持:确保系统和安全始终更新
作者
- Shiv Pullepu,MongoDB
- Luca Napoli,MongoDB
- Ashwin Gangadhar,MongoDB
- Rajesh Vinayagam,MongoDB
