随着每天产生的大量数据和它在我们日常生活中日益重要的作用,全球数据创造的增长是理所当然的。事实上,到2025年,全球数据创造将增加三倍,预计在此之后将出现指数级的数据增长。

来源:Statista,2020年。
鉴于这种数据创造和使用的水平,我们经常听到诸如“结构化数据”和“非结构化数据”等术语。然而,这些术语常常被误解和误用,从糟糕的商业决策到消费者误解他们的个人数据是如何存储、保护和使用的,结果可能各不相同。
继续阅读,了解更多关于结构化和非结构化数据的信息,包括这两种数据类型之间的区别,每种类型数据的存储方式,每种类型数据的最佳用途,以及与结构化和非结构化数据相关的预期未来趋势。
理解结构化和非结构化数据
理解结构化与非结构化数据的关键是掌握每种类型数据的特性、存储和使用的差异。了解用于处理每种类型数据的专用工具以及如何利用它们也是有帮助的。
什么是结构化数据?
结构化数据通常是由从原始格式转换而来的字母数字字符组成,在输入预定的数据模型之前将其转换成预定义的格式。这个数据模型在单元格、行和列中存储结构化数据。一个理解结构化数据的好方法是想象一个Excel数据表,它有单元格、行和列。结构化数据的例子包括财务数据、地址、经纬度和日期。
结构化数据的关键特性
结构化数据的一些关键特性包括
定量数据:结构化数据通常被称为定量数据,因为它包含可衡量的数字或文本值,这些值可以被计数或分析(例如,数字、日期)。
关系数据库:结构化数据存储在关系数据库中,这意味着数据存储在由行和列组成的数据表中。每一列包含某种类型的数据(有时称为属性),每一列中的每个单元格包含实际值。每一行(有时称为元组)包含关于单个实体的数据。
以下示例中,客户信息表包含列(或属性)客户ID、名、姓和地址。每一行由包含每个特定客户信息的单元格组成。

来源:凤凰城纳普全球IT服务,2021年6月。
此数据表说明了结构化数据所在预定义模型中预定义关系是如何创建的(例如,将名、姓、地址属性分配给客户ID)。此外,还可以使用每行中找到的唯一标识符在表之间创建额外的关联,称为主键。
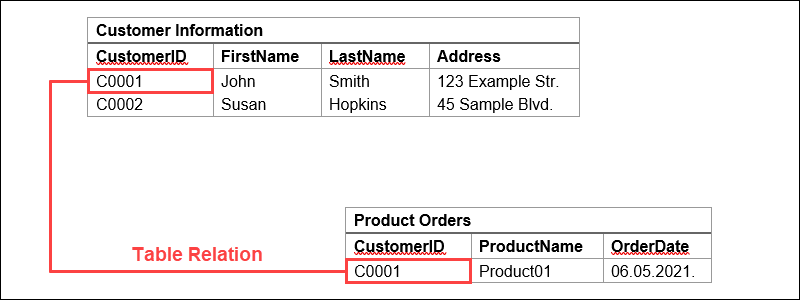
来源:凤凰城纳普全球IT服务,2021年6月。
- 关系数据库管理系统(RDBMS):RDBMS是用于构建和管理关系数据库的程序。RDBMS负责应用逻辑,确保结构化数据以正确的格式被摄入数据库,并放置在正确的表、列和行中。SQL(结构化查询语言)编程语言是RDBMS使用的首选语言。常见的RDBMS类型包括
- Microsoft SQL Server
- Oracle DB
- Amazon Aurora
- MySQL(开源)
- PostgreSQL(开源)
- SQLite(开源)
- 数据仓库:企业经常需要从各种关系数据库中提取结构化数据以进行数据分析。然而,从各种数据库中提取数据可能耗时,因此公司通常会建立数据仓库,这些仓库是来自各种来源的结构化数据的中央存储库。存储在数据仓库中的结构化数据随后通过称为OLAP(在线分析处理)的专用工具进行访问。OLAP工具帮助分析师快速对大量数据进行复杂分析。
结构化数据使用
结构化数据的性质使其适用于各种行业。结构化数据使用的例子包括
会计:会计公司和注册会计师使用存储在数据仓库中的结构化数据记录财务交易、创建财务报表和完成纳税申报。
客户关系管理(CRM):具有预定义格式的结构化数据库中的数据非常适合CRM活动。这包括从管理消费者忠诚度计划(例如,航空公司、杂货店)到通过CRM软件(如Salesforce)管理B2B客户关系的企业。
搜索引擎优化(SEO):结构化数据的使用对于帮助网站在搜索引擎结果页面(SERP)中获得更高的排名至关重要,从而获得更多流量和客户。具体来说,使用结构化数据与未结构化数据相比,确保搜索引擎(如Google)能够通过读取网站的模式标记代码轻松确定网站的内容以及网站内容的品质。
数据分析/数据挖掘:商业智能(BI)分析师和数据科学家使用结构化数据来完成复杂分析——如描述性、诊断性、预测性和规范性分析——涵盖各种行业。数据挖掘,在大型数据集中发现模式而不是应用特定查询于数据,也是结构化数据的常见应用。
机器学习(ML):数据科学家编写的机器学习算法用于在大数据集上快速执行预定义的分析任务——在几秒钟内完成数百次分析,而人工执行则需要数天。
什么是非结构化数据?
非结构化数据是无法通过传统分析方法进行分析或计数的。此外,非结构化数据以原生格式存储,因此无法存储在需要预定义数据模型的关系数据库中。非结构化数据的示例包括卫星图像、音频文件、视频文件,甚至是电子邮件。
了解更多关于非结构化数据的信息。
非结构化数据的关键特征
非结构化数据的一些关键特征包括
定性数据:非结构化数据通常被称为定性数据,因为它是非数字的,可以包含图像,并且本质上是文本密集型的。此外,这种数据很难分析,因为非结构化数据以原生格式存储,并且不适用于传统分析工具的使用。
NoSQL数据库:非结构化数据的格式高度可变。因此,它需要一个针对存储的数据格式和有效访问数据所需的扩展要求进行优化的存储载体(例如,文本文件、视频、扫描文档)。NoSQL数据库,因其不使用SQL编程语言而得名,是非表格式的,并且以与关系表不同的方式存储数据。

来源:Edureka!,2020年5月。
一些NoSQL数据库的例子包括
- 文档数据库,存储类似于JSON(JavaScript对象表示法)对象的数据。每个文档包含字段和值的对。值可以是各种类型,包括字符串、数字、布尔值、数组和对象。
- 键值数据库,这是一种更简单的数据库,其中每个条目包含键和值。
- 宽列存储,在表、行和动态列中存储数据。
- 图数据库,在节点和边中存储数据。节点通常存储有关人员、地点和事物的信息,而边存储有关节点之间关系的信息。
数据湖:由于非结构化数据以原生格式存储而不是预定义的数据模型,因此需要传统数据仓库的替代方案——这种替代方案是数据湖。数据湖是集中式存储库,可以在任何规模上存储非结构化和结构化数据,并在分析时创建数据模型(例如,按读模式)。这种在规模和数据模型方面的灵活性使用户能够处理各种类型的数据,例如音频和视频文件、社交媒体内容、传感器数据(例如时间序列数据)以及定义良好的数据。

非结构化数据的应用
非结构化数据或非关系型数据构成了今天企业数据的一个重大部分。日常生活中使用的非结构化数据示例包括
社交媒体:社交媒体包含半结构化数据(例如,不完全符合数据模型但具有一定结构的数据),但每条社交媒体信息的内容本身是无结构的。
电子邮件:尽管我们有时将其视为半结构化,但电子邮件信息字段是文本字段,不易分析。电子邮件内容还可能包括视频、音频或照片内容,使其成为无结构数据。
文本文件:几乎所有传统的商业文件——包括文字处理文档(例如,Google Docs 或 Microsoft Word)、演示文稿(例如,Microsoft PowerPoint)、笔记和PDF文件——都被归类为无结构数据。
调查问卷回复:当通过调查(例如,文本框)或受访者选择“喜欢”的照片收集开放式反馈时,正在收集无结构数据。
科学数据:科学数据可以包括实地调查、太空探索、地震图像、大气数据、地形数据、天气数据和医疗数据。虽然这些类型的数据可能有基础的结构用于收集,但数据本身往往是无结构的,可能不适用于传统的分析工具和仪表板。
机器和传感器数据:来自物联网(物联网)设备(如手机和平板电脑)的数十亿个小文件产生了大量的无结构数据。此外,企业系统的日志文件,其结构不统一,也创造了大量无结构数据。
比较结构化数据与无结构化数据
结构化和无结构化数据都有价值。解锁数据中存储的价值的关键在于理解这两种类型数据之间的差异以及如何有效利用这些数据类型。
表格:结构化数据和无结构化数据的差异

来源:Lawtomated,结构化数据与无结构化数据:它们是什么以及为什么关心?,2019年4月。
提取数据价值
结构化数据
结构化数据或定量数据的线性、受控特性非常适合统计分析和大数据分析,这些分析使用类似的结构化查询语言(SQL)。这种数据格式的一致性使得数据管理更加简化,并通过机器学习或数据分析师更快地进行搜索和分析任务。此外,这种格式的一致性还适用于数据仓库——鉴于其仪表板功能以及结构化数据管理效率,它是结构化数据的首选存储选项。
无结构化数据
无结构化数据,例如使用MongoDB Atlas这样的NoSQL数据库,也可以从客户调查或社交媒体数据等定性数据中提供高级见解。它还可以提供足够的结构,以便查询非文本资产,从而实现从照片中进行面部识别分析或营销视频内容的A/B测试。
数据的未来是结构化还是无结构化?
分析师预测,到2025年,全球数据领域将增长到163泽字节(nRoad,2022),这并不令人惊讶,因为每个人每天产生的数据量很大,再加上企业和其他组织。组织生成和收集的数据中有80%至90%是无结构的,并且这个数字正在迅速增长。由于这种增长,掌握无结构化数据管理和数据存储至关重要。
例如,金融服务和个人银行等传统上专注于定量、交易数据的监管行业,已经意识到无结构数据是未来金融科技产品和服务的关键。
在Fintech2030的访谈中,行业专家Bob Legters表示,金融机构应该开始思考哪些非结构化数据对他们组织有用,以及他们可以从哪里获取这些非结构化数据。Legters先生还指出,大多数全球金融机构正在使用第三方提供商来获取额外数据集,而不是试图创建自己的非结构化数据版本。预计这一趋势在未来18到24个月内将增加。
话虽如此,许多金融机构可能已经产生了他们寻求的非结构化数据类型,但不知道如何收集、存储和访问它们。实际上,据估计,三分之二的经济数据隐藏在不透明或未结构化的内容源中。这就是与擅长非结构化数据收集、存储、管理和分析的公司合作成为区分和创新的关键所在。
通过收集现有非结构化数据的低垂之果并提取价值,金融科技公司可以在不支付第三方数据费用的情况下获得非结构化数据的好处。此外,通过将非结构化数据存储和管理作为云环境中的后端服务,金融科技公司可以在不牺牲其数据策略演变需求的情况下,保持对其环境和合规的控制。而且,虽然这里讨论的例子是金融科技行业,但这种策略适用于所有行业,因为数据管理和分析的未来显然是非结构化的。
使用MongoDB Atlas免费版发现如何解锁非结构化数据的隐藏价值。