您需要数据库分片吗?
与任何分布式架构一样,数据库分片不是免费的。设置分片、维护每个分片上的数据以及正确路由跨分片的请求都有额外的开销和复杂性。在开始分片之前,考虑以下替代方案是否适合您。
垂直扩展
通过简单地升级您的机器,您可以在不进行分片的情况下进行垂直扩展。添加RAM、升级您的计算机(CPU)或增加数据库可用的存储都是简单的方法,不需要您更改数据库架构或应用程序的设计。 
专用服务或数据库
根据您的用例,您可能只需要将一部分负担转移到其他提供商甚至另一个数据库上。例如,blob或文件存储可以直接转移到云提供商,如Amazon S3。分析或全文搜索可以由专用服务或数据仓库处理。将此特定功能卸载可能比尝试分片整个数据库更有意义。
复制
如果您的数据负载主要是读取,则复制可以提高可用性和读取性能,同时避免了数据库分片的一些复杂性。通过简单地启动数据库的额外副本,可以通过负载均衡或地理位置查询路由来提高读取性能。然而,复制在写入负载方面引入了复杂性,因为每个写入都必须复制到每个副本节点。 
另一方面,如果您的核心应用程序数据库包含大量数据,需要高读取和高写入量,并且/或者您有特定的可用性要求,那么分片数据库可能是前进的方向。让我们看看分片的优势和劣势。
分片的优势
分片可以通过提供 提高读写吞吐量、存储容量 和 高可用性,将您的数据库扩展到几乎无限的程度以处理增加的负载。让我们更详细地看看这些。
- 提高读写吞吐量 — 通过将数据集分布在多个分片上,只要读写操作局限于单个分片,读写操作容量就会增加。
- 提高存储容量 — 同样,通过增加分片数量,您也可以增加总体总存储容量,实现近乎无限的扩展性。
- 高可用性 — 最后,分片以两种方式提供高可用性。首先,由于每个分片都是一个副本集,因此每条数据都进行了复制。其次,即使整个分片变得不可用,由于数据是分布的,数据库整体仍然部分可用,部分模式位于不同的分片上。
分片的劣势
分片确实存在一些缺点,主要是查询结果编译的开销、管理复杂性以及基础设施成本的增加。
- 查询开销 — 每个分片数据库都需要一个独立的机器或服务来理解如何将查询操作路由到适当的分片。这会给每次操作引入额外的延迟。此外,如果查询所需的数据在多个分片之间水平分区,则路由器必须查询每个分片并将结果合并在一起。这可能会使原本简单的操作变得非常昂贵并降低响应时间。
- 管理复杂性 — 对于单个未分片数据库,只需维护数据库服务器本身即可。而对于每个分片数据库,除了管理分片本身之外,还需要维护额外的服务节点。此外,在使用副本的情况下,任何数据更新都必须镜像到每个副本节点。总体而言,分片数据库是一个更复杂的系统,需要更多的管理。
- 基础设施成本增加 — 由于分片本身需要比单个数据库服务器更多的机器和计算能力。虽然这可以让你的数据库扩展到单个机器的限制之外,但每个额外的分片都会带来更高的成本。分布式数据库系统的成本,尤其是如果缺乏适当的优化,可能会非常显著。
在考虑了利弊之后,让我们继续前进并讨论实施。
分片是如何工作的?
为了分片一个数据库,我们必须回答几个基本问题。这些答案将决定你的实现。
首先,数据将如何分布在分片之间? 这是任何分片数据库背后的基本问题。对这个问题的回答将对性能和维护产生影响。更多细节可以在“分片架构和类型”部分找到。
其次,哪些类型的查询将被路由到分片之间? 如果工作负载主要是读操作,复制数据将非常有效地提高性能,你可能根本不需要分片。相比之下,混合读-写工作负载或主要是基于写的工作负载将需要不同的架构。
最后,这些分片将如何维护? 一旦数据库被分片,随着时间的推移,数据需要在各个分片之间重新分配,并且可能需要创建新的分片。根据数据的分布,这可能是一个昂贵的流程,需要提前考虑。
考虑到这些问题,让我们考虑一些分片架构。
分片架构和类型
虽然有许多不同的分片方法,但我们将考虑四种主要类型:范围/动态分片、算法/哈希分片、实体/关系分片和基于地理位置的分片。
范围/动态分片
范围分片 或 动态分片,将记录上的字段作为输入,并根据预定义的范围将该记录分配到适当的分片。范围分片需要为所有查询或写入提供查找表或服务。例如,考虑一组具有从0到50的ID的数据集。一个简单的查找表可能如下所示
| 范围 | 分片ID |
| [0, 20) | A |
| [20, 40) | B |
| [40, 50] | C |
基于范围的字段也称为 分片键。显然,分片键的选择以及范围的设置对于使基于范围的分片有效至关重要。一个差的选择会导致分片不平衡,这会导致性能下降。一个有效的分片键将允许查询针对最少数量的分片进行定位。在我们上面的例子中,如果我们查询ID为10-30的所有记录,那么只需要查询分片A和B。
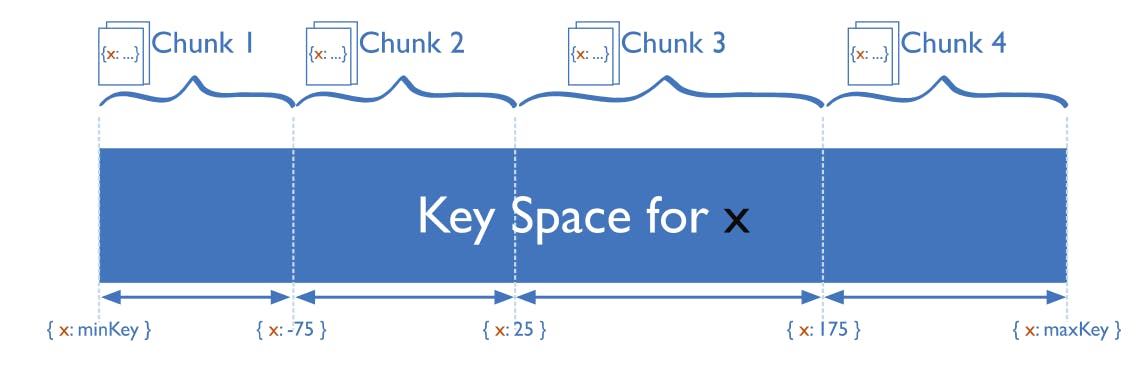 一个有效的分片键有两个关键属性:高 基数 和良好的 频率 分布。 基数 指的是该键的可能值的数量。如果一个分片键只有三个可能的值,那么只能有三个分片。 频率 指的是数据在可能值上的分布。如果95%的记录只有一个分片键值,那么由于这个热点,95%的记录将分配到单个分片。在选择分片键时,要考虑这两个属性。
一个有效的分片键有两个关键属性:高 基数 和良好的 频率 分布。 基数 指的是该键的可能值的数量。如果一个分片键只有三个可能的值,那么只能有三个分片。 频率 指的是数据在可能值上的分布。如果95%的记录只有一个分片键值,那么由于这个热点,95%的记录将分配到单个分片。在选择分片键时,要考虑这两个属性。
基于范围的分片是一种易于理解的横向分区方法,但其有效性将严重依赖于合适的分片键的可用性和适当范围的选取。此外,查找服务可能会成为瓶颈,尽管数据量足够小,这通常不是问题。
算法/哈希分片
算法 分片或 哈希分片,将记录作为输入,并对其应用哈希函数或算法,生成输出或哈希值。然后使用此输出将每个记录分配到适当的分片。
该函数可以取记录上的任何子集作为输入。一个简单的哈希函数示例是使用模运算符与分片数量,如下所示
哈希值 = ID % 分片数量
这与基于范围的分片类似——一组字段决定记录分配到给定的分片。对输入进行哈希处理,即使在没有合适的分片键的情况下,也能使分片之间的分布更加均匀,且不需要维护查找表。然而,也有一些缺点。
首先,多记录的查询操作更有可能分布到多个分片。而基于范围的分片反映了数据在分片之间的自然结构,哈希分片通常不考虑数据的含义。这反映在广播操作发生频率的增加。
其次,重新分片可能会很昂贵。任何对分片数量的更新都可能需要重新平衡所有分片,移动记录。这将很难在不中断系统的情况下完成。
基于实体/关系分片
基于实体的分片 将相关数据保存在单个物理分片上。在关系型数据库(如PostgreSQL、MySQL或SQL Server)中,相关数据通常分布在几个不同的表中。
例如,考虑一个包含用户和支付方式的购物数据库。每个用户都有一组与该用户紧密相关的支付方式。因此,将相关数据保存在同一个分片上可以减少广播操作的需要,从而提高性能。
基于地理位置的分片
基于地理位置的分片 或 地理分片,也将在单个分片上保存相关数据,但在此情况下,数据是通过地理位置相关联的。这本质上是一种基于范围的分片,其中分片键包含地理信息,而分片本身是地理位置。
例如,考虑一个包含“国家”字段的记录集。在这种情况下,通过为每个国家或地区创建一个分片,并在该分片上存储适当的数据,我们可以既提高整体性能,又减少系统延迟。这是一个简单的例子,还有许多其他方式来分配地理分片,这超出了本文的范围。
总结
我们已经定义了分片是什么,讨论了何时使用它,并探索了不同的分片架构。分片是针对具有大量数据需求和大量读写工作负载的应用程序的一个很好的解决方案,但它也带来了额外的复杂性。在开始实施之前,请考虑收益是否大于成本,或者是否有更简单的解决方案。

常见问题解答
什么是分片?
分片和分区有什么区别?
什么是区块链分片?
分片是如何实现的?
在NoSQL中,什么是分片?
何时应该分片数据库?
分片是横向扩展吗?
为什么使用分片?
分片允许存储在单个数据库中的更大数据集。同样,如果请求在机器间正确分配,分片数据集可以处理比单个机器更多的请求。
MongoDB的分片是如何工作的?
在MongoDB中,通过分片是通过分片集群实现的,这些集群由分片、路由器/平衡器以及元数据配置服务器组成。虽然手动设置需要相当多的基础设施设置和配置,但作为数据库即服务提供的MongoDB Atlas使这变得非常简单。只需为MongoDB集群打开选项,并选择分片的数量。
默认设置同时复制和分片数据。这通过使用两种类型的横向扩展提供了高可用性、冗余和增加的读写性能。还包括用于分配查询和数据的路由器。有关更多信息,请点击链接了解更多关于MongoDB Atlas的信息。
还有其他问题吗?请查看分片常见问题解答。